Top 60+ Cloud Computing Interview Questions and Answers

Are you preparing for a technical interview and wondering what kind of cloud-related questions you might face? Cloud computing has become a core skill for both freshers and experienced professionals, and interviewers often test your understanding of concepts, services, and real-world applications.
This guide on Cloud Computing Interview Questions and Answers is designed to help you prepare in a structured and practical way.
In the following sections, you will find carefully curated questions with simple, clear, and interview-focused answers to help you revise concepts quickly and perform better in cloud computing interviews.
Cloud Computing Interview Questions for Freshers
1. Define Cloud Computing and Explain Its Key Characteristics
Cloud computing is a model that delivers computing resources such as servers, storage, databases, and networking over the internet on demand. Instead of owning physical infrastructure, users access services through cloud providers.
Key Characteristics:
- On-Demand Self-Service – Resources can be provisioned automatically without human intervention.
- Broad Network Access – Services are accessible over the internet from various devices.
- Resource Pooling – Multiple users share a pooled infrastructure securely.
- Rapid Elasticity – Resources can scale up or down quickly.
- Measured Service – Usage is monitored and billed based on consumption.
2. Compare IaaS, PaaS, and SaaS in Terms of Control and Responsibility
Cloud service models differ based on how much control the customer retains and how much responsibility the provider manages.
| Feature | IaaS | PaaS | SaaS |
| Infrastructure Control | High | Medium | Low |
| OS & Runtime Management | User | Provider | Provider |
| Application Control | User | User | Provider |
| Example | AWS EC2 | Google App Engine | Gmail |
- IaaS gives maximum control over infrastructure.
- PaaS manages runtime and OS, focusing on application development.
- SaaS delivers fully managed software over the internet.
3. How Does Virtualization Make Cloud Infrastructure Scalable?
Virtualization allows multiple virtual machines (VMs) to run on a single physical server. This abstraction enables better resource utilization and flexible allocation.
How It Enables Scalability:
- Physical resources are divided into multiple virtual instances.
- VMs can be created or removed quickly.
- Hardware utilization improves through resource sharing.
- Enables horizontal scaling by adding more virtual machines.
- Virtualization forms the foundation of cloud infrastructure by separating hardware from software environments.
4. Explain the Working of a Hypervisor in a Cloud Environment
A hypervisor is software that creates and manages virtual machines by allocating hardware resources such as CPU, memory, and storage.
Working Process:
- Runs on physical hardware.
- Divides system resources among multiple VMs.
- Isolates each VM for security and performance.
- Monitors resource usage and optimizes allocation.
Types:
- Type 1 (Bare-Metal) – Runs directly on hardware (e.g., VMware ESXi).
- Type 2 (Hosted) – Runs on top of an operating system (e.g., VirtualBox).
Cloud providers mainly use Type 1 hypervisors for better performance and security.
5. Distinguish Between Public, Private, and Hybrid Cloud with Practical Use Cases
Cloud deployment models define how infrastructure is hosted and accessed.
| Model | Description | Use Case Example |
| Public Cloud | Shared infrastructure managed by third party | Hosting web applications |
| Private Cloud | Dedicated infrastructure for one organization | Banking systems |
| Hybrid Cloud | Combination of public and private cloud | Sensitive data in private, apps in public |
Practical Perspective:
- Public cloud is cost-effective and scalable.
- Private cloud offers more control and security.
- Hybrid cloud balances flexibility and compliance.
6. Define Elasticity from Scalability with Examples
Elasticity and scalability both relate to resource adjustment but differ in behavior.
Scalability:
- Ability to increase system capacity to handle growing workload.
- Vertical scaling: Add more CPU/RAM.
- Horizontal scaling: Add more servers.
- Example: Increasing server size during company growth.
Elasticity:
- Ability to automatically adjust resources based on demand in real time.
- Scales up during peak hours.
- Scales down during low usage.
- Example: E-commerce website during festive sales.
Elasticity is dynamic, while scalability can be planned growth.
7. Explain How Multi-Tenancy Works in Cloud Platforms
Multi-tenancy allows multiple customers (tenants) to share the same infrastructure while keeping their data isolated and secure.
How It Works:
- Resources are logically partitioned.
- Data isolation is enforced at application or database level.
- Access control policies restrict unauthorized access.
- Infrastructure costs are distributed among tenants.
Example: Multiple companies using the same SaaS CRM platform.
8. Why Is Load Balancing Essential in Distributed Cloud Systems?
Load balancing distributes incoming traffic across multiple servers to ensure reliability and performance.
Importance:
- Prevents server overload.
- Improves application availability.
- Reduces response time.
- Enables fault tolerance.
- Supports auto-scaling environments.
Without load balancing, a single server failure can disrupt the entire application.
9. How Does Serverless Architecture Reduce Operational Overhead?
Serverless computing allows developers to run code without managing servers. The cloud provider handles provisioning, scaling, and maintenance.
How It Reduces Overhead:
- No server management required.
- Automatic scaling.
- Pay only for execution time.
- Built-in availability and fault tolerance.
Example: AWS Lambda executes functions only when triggered.
Developers focus on business logic instead of infrastructure management.
10. Explain the Role of SLAs in Cloud Service Agreements
A Service Level Agreement (SLA) defines the performance and availability guarantees provided by the cloud provider.
Key Components:
- Uptime percentage (e.g., 99.9% availability).
- Performance benchmarks.
- Support response times.
- Compensation terms for downtime.
SLAs help organizations evaluate reliability and plan business continuity strategies.
11. Compare object storage, block storage, and file storage.
| Feature | Object Storage | Block Storage | File Storage |
| Data Structure | Stores data as objects with metadata | Stores data in fixed-size blocks | Stores data in hierarchical file system |
| Access Method | HTTP/REST APIs | Attached as disk volumes | Network file protocols (NFS/SMB) |
| Scalability | Highly scalable | Limited by attached instance | Moderate scalability |
| Performance | Optimized for large unstructured data | High performance, low latency | Shared file access |
| Use Case | Backups, media files, logs | Databases, virtual machines | Shared file systems |
Object storage is ideal for unstructured data, block storage is suitable for high-performance applications like databases, and file storage is used when multiple systems need shared file access.
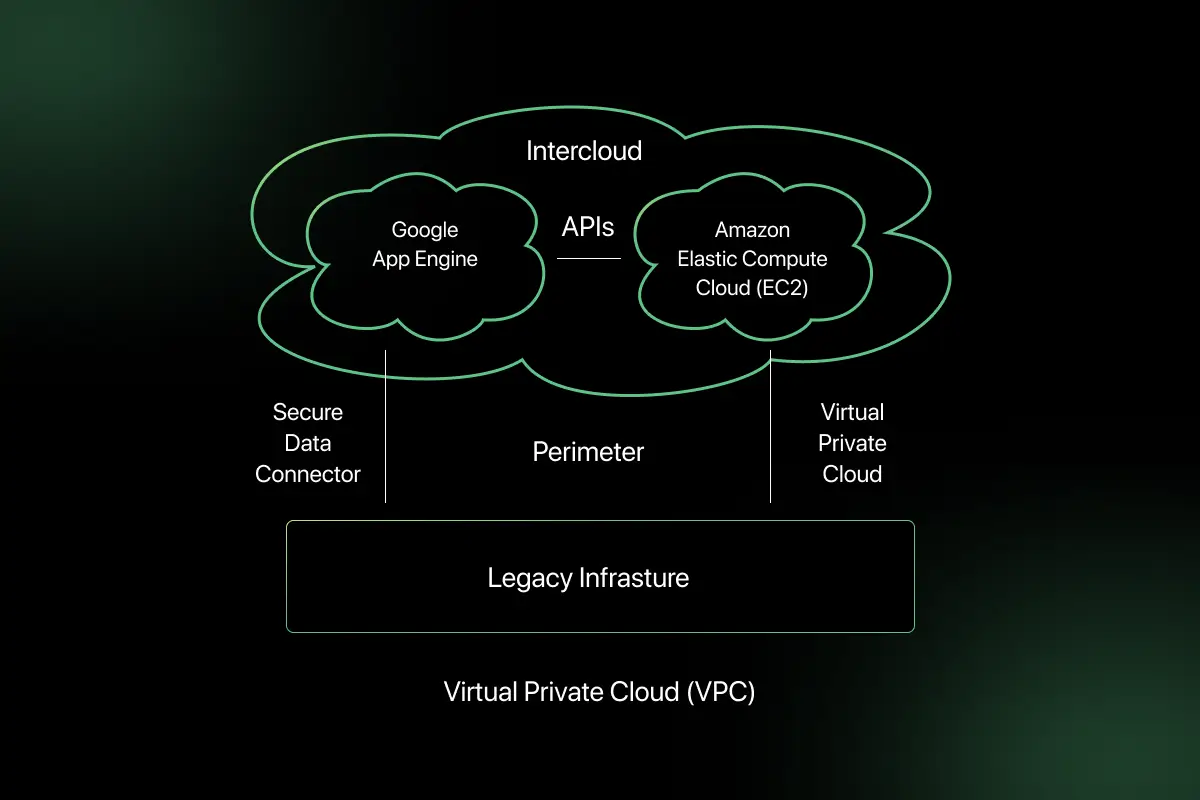
12. Explain how a Virtual Private Cloud (VPC) isolates resources.
A Virtual Private Cloud is a logically isolated network within a public cloud environment. It allows organizations to define their own IP address ranges, subnets, and routing rules.
- VPC isolation works by segmenting cloud infrastructure into private networks.
- Resources inside a VPC communicate securely using private IP addresses.
- Access is controlled through routing tables, security groups, and network access control lists.
- This ensures that external traffic cannot directly access internal resources unless explicitly allowed.
13. How do security groups protect cloud resources?
Security groups act as virtual firewalls that control inbound and outbound traffic to cloud resources such as virtual machines. They operate at the instance level and define rules based on protocol, port number, and source or destination IP address.
Only traffic that matches defined rules is allowed. By restricting unauthorized access and allowing only necessary communication, security groups reduce exposure to network-based attacks.
14. Describe the shared responsibility model in cloud security.
The shared responsibility model defines how security duties are divided between the cloud provider and the customer.
- The provider is responsible for securing the underlying infrastructure, including hardware, networking, and physical data centers.
- The customer is responsible for securing operating systems, applications, configurations, and data.
This model ensures that while providers maintain infrastructure security, users must properly configure and manage their own resources.
15. Explain the importance of encryption in cloud environments.
Encryption protects sensitive data by converting it into unreadable form unless accessed with the proper keys. In cloud environments, encryption prevents unauthorized access during storage and transmission. It helps maintain confidentiality, supports compliance requirements, and reduces risks of data breaches.
Encryption is typically implemented in two forms: encryption at rest for stored data and encryption in transit for data being transferred over networks.
16. Compare AWS EC2, Azure Virtual Machines, and Google Compute Engine.
| Feature | AWS EC2 | Azure Virtual Machines | Google Compute Engine |
| Provider | Amazon Web Services | Microsoft Azure | Google Cloud Platform |
| Instance Customization | Wide variety of instance types | Strong enterprise integration | High-performance custom machine types |
| Pricing Model | On-demand, reserved, spot | Pay-as-you-go, reserved | Sustained use discounts |
| Integration | Deep AWS ecosystem | Strong Microsoft product integration | Optimized for analytics and AI workloads |
| Market Adoption | Largest market share | Popular in enterprise | Strong in data-driven applications |
All three services provide scalable virtual machines, but differ in ecosystem integration, pricing flexibility, and enterprise alignment.
17. Explain how AWS S3 differs from Azure Blob Storage.
| Feature | AWS S3 | Azure Blob Storage |
| Storage Type | Object storage | Object storage |
| Access Model | Bucket-based structure | Container-based structure |
| Durability | 99.999999999% | 99.999999999% |
| Tier Options | Standard, IA, Glacier | Hot, Cool, Archive |
| Integration | Strong AWS service integration | Strong Azure ecosystem integration |
Both are object storage services designed for scalability and durability. Differences mainly lie in terminology, pricing tiers, and ecosystem integration.
18. How does Google Cloud’s App Engine simplify deployment?
Google App Engine is a fully managed Platform as a Service that abstracts infrastructure management from developers.
- It automatically provisions servers, handles scaling, manages load balancing, and integrates monitoring tools.
- Developers only deploy application code without configuring virtual machines or managing operating systems.
- This reduces operational complexity and accelerates development cycles.
19. What role does IAM play across AWS, Azure, and GCP?
Identity and Access Management controls authentication and authorization across cloud platforms.
- IAM defines who can access resources and what actions they can perform.
- It uses policies, roles, and permissions to enforce least privilege access.
- Across AWS, Azure, and GCP, IAM ensures secure identity verification, prevents unauthorized access, and supports compliance requirements.
20. Explain how cloud pricing models impact application design.
Cloud pricing models influence how applications are architected for cost efficiency. Since cloud providers charge based on usage, application design must optimize resource consumption. Architects often use auto-scaling, serverless computing, and reserved instances to reduce costs.
Efficient storage selection, load balancing, and monitoring also help prevent unnecessary expenses. Designing with cost-awareness ensures performance while maintaining budget control.

Cloud Computing Interview Questions for Intermediate
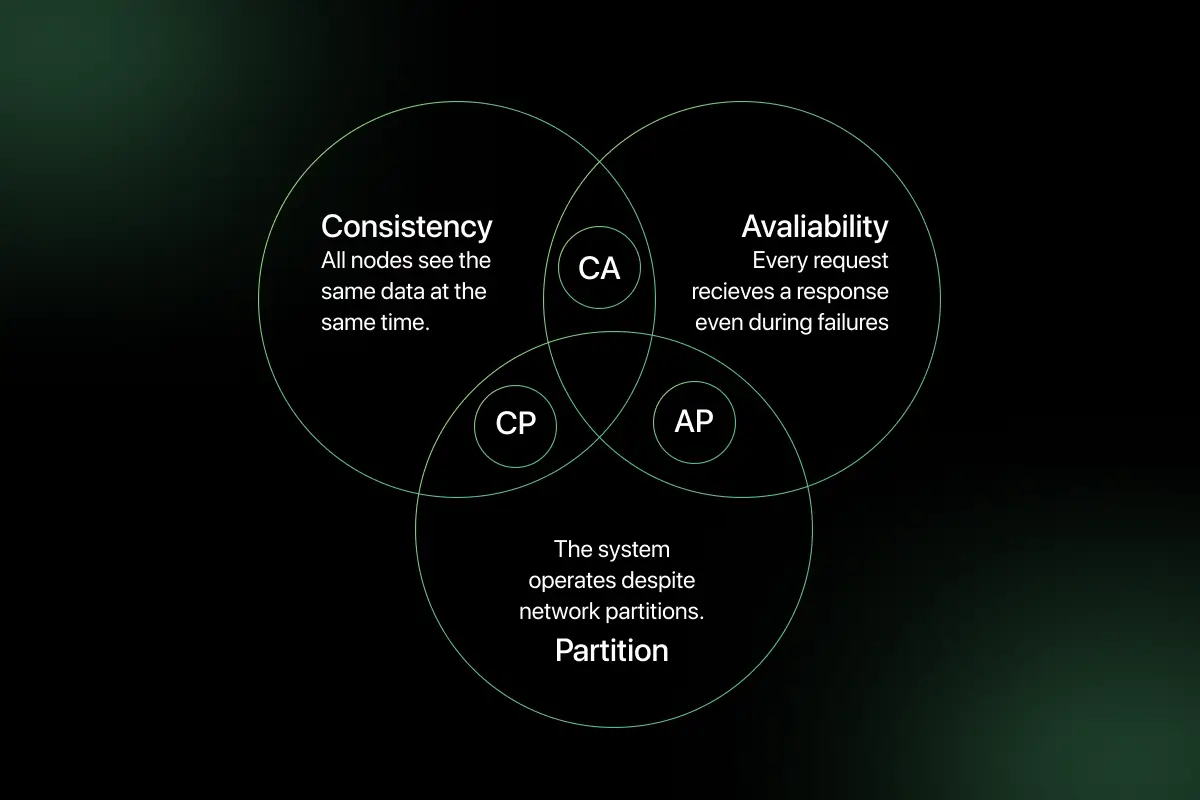
1. Explain the CAP theorem and its relevance in cloud databases.
The CAP theorem states that in a distributed system, it is impossible to simultaneously guarantee Consistency, Availability, and Partition Tolerance. A system can provide only two of these three properties at the same time.
- Consistency ensures every read receives the latest write.
- Availability ensures every request receives a response, even if some nodes fail.
- Partition tolerance means the system continues operating despite network failures between nodes.
In cloud databases, network partitions are unavoidable, so systems must choose between consistency and availability.
For example, relational databases like Amazon RDS prioritize consistency, while distributed NoSQL systems like DynamoDB may prioritize availability with eventual consistency.
2. Compare high availability and fault tolerance in system design.
| Feature | High Availability | Fault Tolerance |
| Definition | Minimizes downtime | Prevents downtime entirely |
| Failure Handling | System may briefly interrupt | No interruption during failure |
| Infrastructure | Redundant components | Fully duplicated components |
| Cost | Moderate | Higher due to duplication |
| Example | Multi-AZ deployment | Active-active multi-region setup |
High availability reduces downtime through redundancy, while fault tolerance ensures continuous operation even if a component fails.
3. How does auto-scaling work in AWS or Azure?
Auto-scaling automatically adjusts the number of compute instances based on workload demand.
- In AWS, Auto Scaling Groups monitor metrics like CPU usage through CloudWatch. When thresholds are exceeded, new EC2 instances are launched. When demand drops, instances are terminated.
- In Azure, Virtual Machine Scale Sets perform similar actions by monitoring performance metrics and scaling instances dynamically.
Auto-scaling ensures cost efficiency and performance optimization by matching resources to demand.
4. Explain the concept of cloud-native architecture.
Cloud-native architecture refers to designing applications specifically for cloud environments rather than adapting traditional systems.
It typically includes:
- Microservices-based structure
- Containerization
- Continuous integration and deployment
- Automated scaling
- Resilient and loosely coupled services
Cloud-native systems leverage managed services, distributed systems principles, and automation to improve scalability and resilience.
5. How do availability zones and regions improve reliability?
Cloud providers divide infrastructure into regions and availability zones to reduce failure impact.
A region is a geographic location containing multiple data centers. An availability zone is an isolated data center within a region.
Deploying applications across multiple availability zones protects against data center failures. Multi-region deployment protects against regional outages. This layered distribution improves system reliability and disaster recovery capability.
6. Compare containers and virtual machines in terms of performance and use cases.
| Feature | Containers | Virtual Machines |
| Virtualization Type | OS-level | Hardware-level |
| Resource Usage | Lightweight | Higher resource usage |
| Startup Time | Seconds | Minutes |
| Isolation | Process-level | Full OS isolation |
| Use Case | Microservices, DevOps | Legacy apps, full OS control |
Containers share the host operating system, making them faster and more efficient. Virtual machines provide stronger isolation but require more resources.
7. How does a Content Delivery Network (CDN) improve latency?
A Content Delivery Network distributes content across multiple geographically distributed edge servers.
When a user requests content, it is served from the nearest edge location instead of the origin server. This reduces round-trip time and improves response speed.
CDNs also reduce load on the origin server, improve availability, and provide caching mechanisms for static content such as images, videos, and scripts.
Example: Amazon CloudFront or Azure CDN serving global users efficiently.
8. How does AWS Lambda differ from EC2 in execution model?
| Feature | AWS Lambda | AWS EC2 |
| Execution Model | Event-driven | Instance-based |
| Server Management | Fully managed | User-managed |
| Scaling | Automatic | Manual or Auto Scaling |
| Billing | Per execution time | Per running instance |
| Use Case | Short-lived functions | Long-running applications |
Lambda executes code in response to events without provisioning servers. EC2 requires users to manage virtual machines and operating systems.
9. Explain how Kubernetes manages container orchestration.
Kubernetes automates deployment, scaling, and management of containerized applications.
It organizes containers into pods and schedules them across cluster nodes. It continuously monitors container health and restarts failed pods automatically. Kubernetes also manages service discovery, load balancing, and rolling updates.
Through controllers and declarative configuration, Kubernetes ensures the desired state of the application is maintained.
10. How does Terraform implement Infrastructure as Code?
Terraform implements Infrastructure as Code by allowing infrastructure to be defined using configuration files written in HashiCorp Configuration Language (HCL).
These configuration files describe resources such as virtual machines, networks, and storage. Terraform compares the desired state with the current state and generates an execution plan. After approval, it provisions or updates the infrastructure automatically.
This approach ensures consistency, repeatability, and version control of cloud infrastructure across environments.
11. Compare Azure Resource Manager templates and Terraform.
| Feature | Azure Resource Manager (ARM) Templates | Terraform |
| Scope | Azure-specific | Multi-cloud (AWS, Azure, GCP) |
| Language | JSON | HashiCorp Configuration Language (HCL) |
| State Management | Managed by Azure | Maintains state file locally or remotely |
| Portability | Limited to Azure | Works across multiple providers |
| Use Case | Native Azure deployments | Cross-cloud infrastructure automation |
ARM templates are tightly integrated with Azure and suited for Azure-only environments. Terraform provides broader flexibility and is preferred when managing infrastructure across multiple cloud platforms.
12. How does Google Cloud Pub/Sub support event-driven systems?
Google Cloud Pub/Sub is a fully managed messaging service that enables asynchronous communication between services.
It uses a publish-subscribe model where producers publish messages to topics and subscribers receive them independently. This decouples services, allowing systems to scale independently and process events in real time.
Pub/Sub ensures reliable message delivery, supports horizontal scaling, and enables event-driven architectures such as microservices communication and streaming data pipelines.
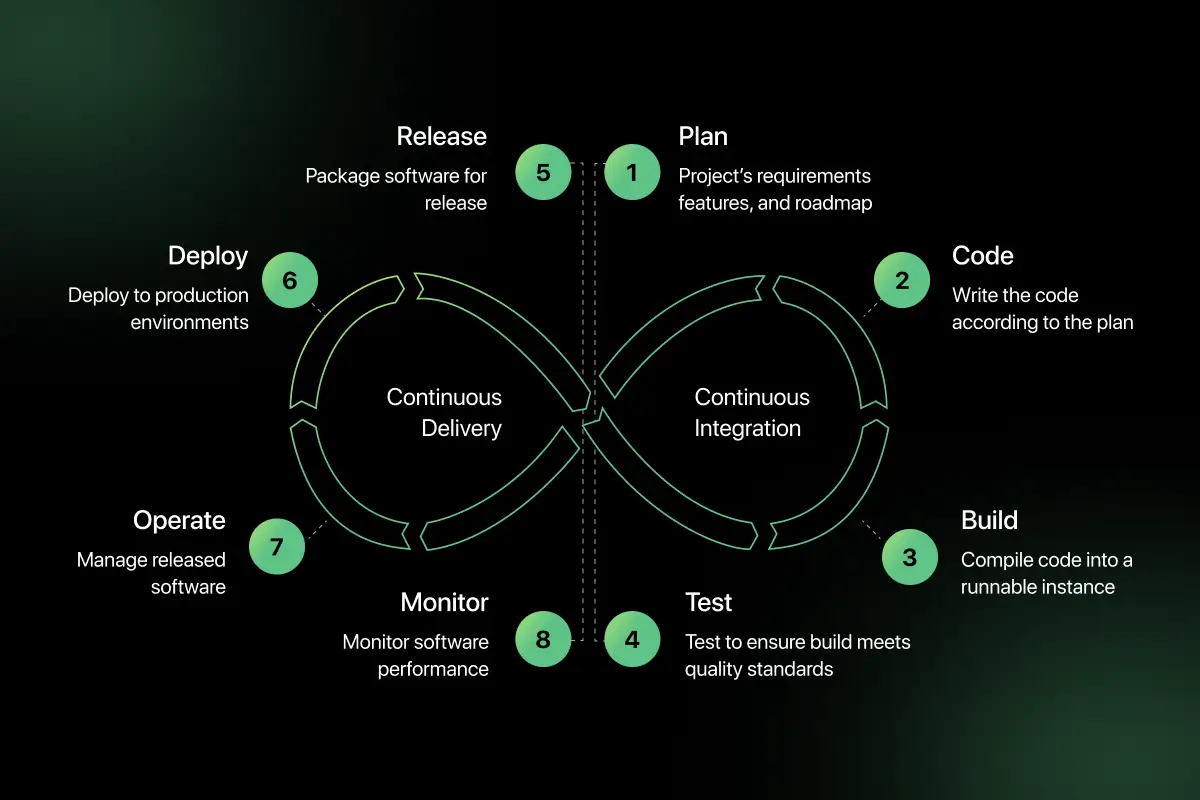
13. Explain how CI/CD pipelines integrate with cloud platforms.
CI/CD pipelines automate the process of building, testing, and deploying applications.
In cloud environments:
- Source code is pushed to a repository.
- CI tools build and test the application.
- Artifacts are stored in cloud repositories.
- CD tools deploy applications to cloud services such as EC2, Kubernetes, or App Service.
- Monitoring tools validate deployment health.
Cloud-native CI/CD services like AWS CodePipeline, Azure DevOps, and Google Cloud Build integrate directly with cloud infrastructure to enable automated and consistent deployments.
14. Explain how subnetting works inside a VPC.
Subnetting divides a VPC’s IP address range into smaller segments to organize resources logically.
Each subnet operates within a specific availability zone. Subnets can be public or private depending on routing configurations. Public subnets allow internet access through an internet gateway, while private subnets restrict external access.
Subnetting improves security, traffic management, and network segmentation within cloud infrastructure.
15. Compare security groups and network ACLs.
| Feature | Security Groups | Network ACLs |
| Level | Instance-level | Subnet-level |
| Rule Type | Allow rules only | Allow and deny rules |
| Evaluation | Stateful | Stateless |
| Application | Applied to individual resources | Applied to entire subnet |
| Example Use | Restrict port access to VM | Block specific IP ranges |
Security groups provide fine-grained access control for instances, while network ACLs provide broader network-level traffic filtering.
16. Explain encryption at rest vs encryption in transit.
| Feature | Encryption at Rest | Encryption in Transit |
| Purpose | Protect stored data | Protect data during transmission |
| Example | Encrypted database storage | HTTPS communication |
| Risk Prevented | Unauthorized storage access | Data interception |
| Implementation | Disk-level encryption | SSL/TLS protocols |
Encryption at rest secures stored data, while encryption in transit protects data moving between systems or over networks.
17. Write pseudocode for an auto-scaling policy based on CPU threshold.
Monitor CPU_Usage every 60 seconds
IF CPU_Usage > 70% FOR 5 consecutive minutes:
Increase instance_count by 1
ELSE IF CPU_Usage < 30% FOR 10 consecutive minutes:
Decrease instance_count by 1
Ensure instance_count remains within min and max limits
This logic ensures dynamic scaling while preventing rapid fluctuations.
18. Design a retry mechanism with exponential backoff for API failures.
Exponential backoff increases the wait time between retry attempts to avoid overwhelming the system.
Set max_retries = 5
Set base_delay = 2 seconds
FOR attempt in 1 to max_retries:
response = call_API()
IF response is successful:
Break
ELSE:
wait_time = base_delay ^ attempt
Wait for wait_time
This strategy reduces server overload and improves system stability during temporary failures.
19. Outline steps to calculate estimated monthly cost of a cloud application.
- Identify compute resources (VMs, containers, serverless).
- Estimate storage requirements and data transfer.
- Determine expected usage hours per month.
- Include managed services such as databases or load balancers.
- Apply pricing models (on-demand, reserved, spot).
- Use cloud pricing calculators to validate estimation.
- Add buffer for scaling or unexpected traffic spikes.
Cost estimation requires analyzing workload patterns and resource consumption.
20. How would you analyze performance bottlenecks in a cloud-hosted web application?
Performance analysis involves systematic monitoring and diagnosis.
- Review CPU, memory, and disk usage metrics.
- Analyze application logs for errors or slow queries.
- Check database performance and indexing.
- Evaluate network latency and bandwidth.
- Inspect load balancer and scaling configurations.
- Use monitoring tools such as CloudWatch or Azure Monitor.
Identifying bottlenecks requires isolating whether the issue is compute, storage, database, or network-related.
Cloud Computing Interview Questions for Experienced
1. Explain eventual consistency and strong consistency in distributed cloud databases.
Consistency models define how quickly data updates are reflected across distributed systems.
- Strong consistency guarantees that once data is written, all subsequent reads return the most recent value. It ensures immediate synchronization across nodes but may increase latency.
- Eventual consistency allows temporary differences between replicas. Updates propagate asynchronously, and all nodes eventually reach the same state.
Strong consistency is preferred in banking or financial systems. Eventual consistency is suitable for large-scale systems like product catalogs or social media feeds where slight delays are acceptable.
2. Compare monolithic and microservices architectures in cloud environments.
| Feature | Monolithic Architecture | Microservices Architecture |
| Structure | Single unified codebase | Multiple independent services |
| Deployment | Entire app deployed together | Services deployed independently |
| Scalability | Scales as a whole | Scales per service |
| Fault Isolation | Single failure may affect entire app | Failure isolated to specific service |
| Use Case | Small applications | Large, scalable systems |
Monolithic systems are simpler to develop initially, while microservices offer better scalability, flexibility, and resilience in cloud-native environments.
3. How does event-driven architecture differ from request-driven architecture?
| Feature | Event-Driven Architecture | Request-Driven Architecture |
| Trigger | Events (e.g., message arrival) | Direct client request |
| Coupling | Loosely coupled services | Tightly coupled interactions |
| Communication | Asynchronous | Synchronous |
| Scalability | High scalability | Limited by synchronous flow |
| Example | Pub/Sub systems | REST API calls |
Event-driven systems react to events published to message queues, improving decoupling and scalability. Request-driven systems rely on direct client-server communication.
4. Explain the trade-offs between relational and NoSQL databases in cloud systems.
| Feature | Relational Databases | NoSQL Databases |
| Schema | Fixed schema | Flexible schema |
| Consistency | Strong consistency | Often eventual consistency |
| Scalability | Vertical scaling | Horizontal scaling |
| Query Capability | Complex SQL queries | Limited query patterns |
| Example | Amazon RDS | DynamoDB, MongoDB |
Relational databases provide strong ACID guarantees and are ideal for structured transactional systems. NoSQL databases are better suited for distributed, high-scale, and flexible data models.
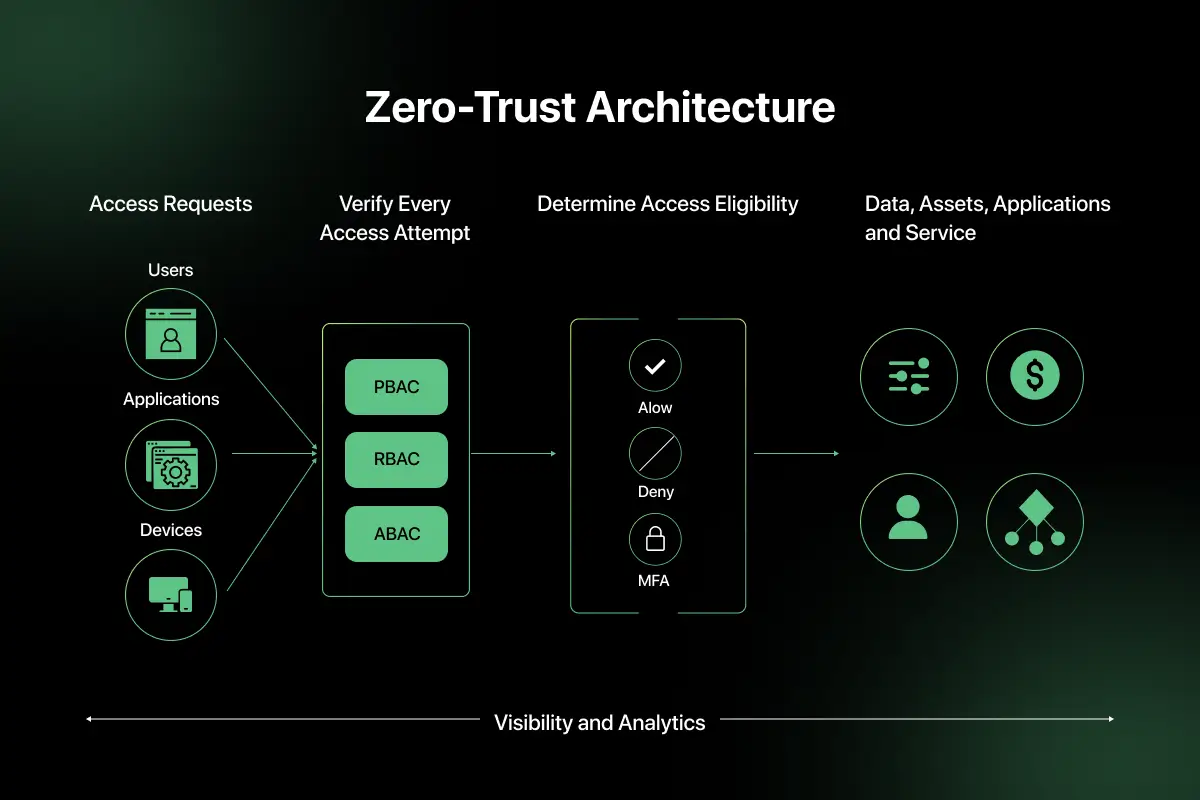
5. How does zero-trust architecture enhance cloud security?
Zero-trust architecture assumes that no user or system should be trusted by default, even inside the network perimeter.
It enforces strict identity verification, least privilege access, and continuous monitoring. Access decisions are based on user identity, device health, and contextual risk.
In cloud environments, zero trust is implemented using IAM policies, network segmentation, and multi-factor authentication. This reduces the risk of insider threats and lateral movement within networks.
6. Explain how service meshes improve microservices communication.
A service mesh manages communication between microservices using a dedicated infrastructure layer.
It provides features such as:
- Traffic routing and load balancing
- Mutual TLS encryption
- Observability and monitoring
- Retry and circuit breaker mechanisms
Tools like Istio or Linkerd inject sidecar proxies into each service, handling communication transparently. This simplifies security and resilience without modifying application code.
7. Compare blue-green and canary deployment strategies.
| Feature | Blue-Green Deployment | Canary Deployment |
| Deployment Model | Two identical environments | Gradual rollout to subset of users |
| Risk Level | Low risk, instant switch | Controlled risk, gradual exposure |
| Rollback | Immediate switch back | Rollback after testing subset |
| Resource Cost | Requires duplicate environment | Uses same environment with phased rollout |
| Use Case | Major releases | Incremental updates |
Blue-green deployment switches traffic between two environments. Canary deployment releases new features gradually to monitor impact before full rollout.
8. How does distributed tracing help in debugging cloud-native systems?
Distributed tracing tracks requests as they move across multiple microservices.
Each service generates trace IDs that allow developers to visualize request flow. This helps identify latency issues, failed dependencies, or bottlenecks.
Tools like AWS X-Ray or Google Cloud Trace provide end-to-end visibility, making it easier to debug complex distributed systems.
9. How would you design cross-region replication in AWS?
Cross-region replication improves disaster recovery and availability.
Design steps:
- Deploy primary infrastructure in one AWS region.
- Configure secondary region with replicated resources.
- Use Amazon RDS cross-region read replicas for databases.
- Enable S3 cross-region replication for object storage.
- Use Route 53 for DNS failover.
- Implement health checks for automatic traffic redirection.
This setup ensures business continuity in case of regional outages.
10. Compare AWS IAM roles with Azure Managed Identities.
| Feature | AWS IAM Roles | Azure Managed Identities |
| Purpose | Grant temporary permissions | Provide identity for Azure resources |
| Credential Management | Temporary security credentials | Automatically managed by Azure |
| Assignment | Attached to EC2, Lambda, etc. | Assigned to Azure VMs, App Services |
| Secret Handling | No hardcoded credentials needed | No credentials stored in code |
| Scope | AWS services | Azure services |
Both mechanisms eliminate hardcoded credentials and provide secure access control for cloud resources, improving security posture.
11. How does Google Cloud’s BigQuery differ from traditional data warehouses?
BigQuery is a fully managed, serverless cloud data warehouse designed for fast analytics at scale. Traditional data warehouses usually require capacity planning, infrastructure setup, and ongoing maintenance.
BigQuery separates compute and storage, so you can scale query performance without managing servers. It also supports near real time ingestion and uses a pay for what you query model.
Example: For analyzing large clickstream data daily, BigQuery can run parallel queries quickly without provisioning a dedicated cluster, while traditional warehouses often need pre sized infrastructure.
12. Explain how Kubernetes handles pod scheduling and self-healing.
Kubernetes schedules pods by selecting the best node based on resource availability and scheduling rules.
Scheduling is influenced by CPU and memory requests, node labels, taints and tolerations, and affinity or anti-affinity rules. Once scheduled, Kubernetes continuously watches pod health.
Self-healing happens through:
- Restarting containers when they fail
- Recreating pods if a node becomes unavailable
- Rescheduling pods onto healthy nodes
- Maintaining desired replicas via Deployments and ReplicaSets
Example: If a pod crashes due to a temporary issue, Kubernetes restarts it automatically. If the node fails, it recreates the pod on another node.
13. How do cloud-native monitoring tools like CloudWatch, Azure Monitor, and Stackdriver differ?
| Feature | AWS CloudWatch | Azure Monitor | Google Cloud Operations (Stackdriver) |
| Cloud Platform | AWS | Azure | Google Cloud |
| Core Strength | Metrics, logs, alarms, AWS service integration | Unified observability across Azure resources and apps | Strong integration with GCP, logging and tracing |
| Alerting | Alarms, EventBridge integration | Alerts with action groups | Alerting policies with SLO support |
| Tracing Support | Works with AWS X-Ray | Works with Application Insights | Includes Cloud Trace and Error Reporting |
| Typical Use | Monitoring EC2, Lambda, RDS, EKS | Monitoring VMs, App Services, AKS | Monitoring GCE, GKE, BigQuery, Pub/Sub |
All three provide metrics, logs, and alerting, but differ mainly in ecosystem integration and observability tooling around tracing and app performance.
14. Explain strategies to optimize cloud cost without compromising performance.
Cloud cost optimization is about reducing waste while keeping workloads reliable and responsive.
Common strategies include:
- Right-size instances based on actual usage patterns
- Use auto scaling to match demand instead of fixed capacity
- Choose reserved instances or savings plans for predictable workloads
- Use spot instances for fault tolerant batch jobs
- Pick appropriate storage tiers for access frequency
- Reduce data transfer costs using CDNs and regional design
- Set budgets, alerts, and tagging for cost visibility
Example: Running a development environment only during working hours and shutting it down overnight can significantly reduce monthly compute cost.
15. How do you implement infrastructure drift detection?
Infrastructure drift is the difference between your declared infrastructure and what is actually running in the cloud.
Drift detection can be implemented by:
Using Infrastructure as Code as the single source of truth
Running periodic plan checks
- Terraform plan to detect untracked changes
- CloudFormation drift detection for AWS stacks
Enforcing change through CI CD pipelines only
Logging and alerting on console based changes using audit trails
- AWS CloudTrail
- Azure Activity Logs
- GCP Audit Logs
A good practice is to run drift checks daily or weekly and block manual changes unless they are later committed back into IaC.
16. Compare disaster recovery strategies: backup & restore, pilot light, warm standby.
| Strategy | What It Means | Recovery Time | Cost | Typical Use |
| Backup and Restore | Keep backups and rebuild during disaster | Highest RTO | Lowest | Small apps, non critical workloads |
| Pilot Light | Minimal core services running, scale up during disaster | Medium RTO | Medium | Moderate criticality systems |
| Warm Standby | Reduced capacity version always running | Lower RTO | Higher | Business critical systems |
Backup and restore is simplest and cheapest but slowest to recover. Warm standby is faster but costs more due to running duplicate infrastructure.
17. How would you secure secrets management in large-scale cloud systems?
Secrets should never be hardcoded in code repositories, configuration files, or container images.
A secure approach includes:
- Use managed secrets services
- AWS Secrets Manager or SSM Parameter Store
- Azure Key Vault
- Google Secret Manager
- Enforce least privilege access via IAM
- Rotate secrets automatically and regularly
- Audit secret access through logs
- Inject secrets at runtime through environment variables or sidecar agents
- Encrypt secrets at rest and in transit
Example: A microservices app can fetch DB credentials securely from Key Vault or Secrets Manager at startup and rotate them without redeploying all services.
18. What architectural decisions influence system resilience in multi-region deployments?
Multi-region resilience depends on design choices that reduce single points of failure.
Key decisions include:
- Active active vs active passive region strategy
- Data replication model, synchronous vs asynchronous
- Regional failover using DNS or traffic managers
- Stateless service design with externalized state
- Use of multi AZ within each region
- Circuit breakers and retries to handle region level failures
- Observability and automated incident response
Example: A global application using Route 53 latency based routing with health checks can automatically direct users to a healthy region during an outage.
19. If a multi-tier cloud application shows intermittent latency spikes, how would you approach diagnosis?
Start by narrowing down which tier is causing the delay and whether the spikes correlate with traffic, scaling, or external dependencies.
A structured approach:
- Check monitoring dashboards for CPU, memory, disk, and network spikes across tiers
- Review load balancer metrics and request latency percentiles
- Inspect application logs for slow endpoints and error patterns
- Analyze database performance, slow queries, locks, connection pool saturation
- Check cache hit ratio and eviction rates
- Review recent deployments or configuration changes
- Use distributed tracing to locate the slow service and dependency
Example: If spikes occur during auto scaling, the issue could be cold starts, slow pod startup, or insufficient connection pool tuning.
20. If a Kubernetes cluster experiences repeated pod crashes, how would you systematically investigate?
Repeated pod crashes usually indicate application failures, misconfiguration, or resource limits.
Systematic steps:
- Check pod status and restart reason
- Look for CrashLoopBackOff, OOMKilled, ImagePullBackOff
- Inspect logs of the crashing container
- Describe the pod to see events and readiness probe failures
- Verify resource requests and limits, especially memory
- Check configuration errors in ConfigMaps and Secrets
- Validate dependency connectivity such as DB endpoints and service discovery
- If only one node shows issues, check node health, disk pressure, and kubelet logs
Example: If pods are OOMKilled, increase memory limits or fix memory leaks, and ensure requests match real usage.
Scenario-Based Questions for Cloud Computing Interviews
1. A small e-commerce website hosted on a single EC2 instance crashes during festive sales due to high traffic. As a beginner cloud engineer, how would you improve its availability?
The main issue is a single point of failure and lack of scalability.
To improve availability:
- Deploy the application behind a load balancer.
- Use an Auto Scaling Group to automatically add instances during traffic spikes.
- Store session data in a shared cache like Redis instead of local memory.
- Move static content to object storage such as S3 with CDN enabled.
- Deploy instances across multiple availability zones.
This ensures the application can scale during peak demand and remain available even if one instance fails.
2. Your company stores important documents in cloud storage, but management is worried about data security. What steps would you recommend?
Data security concerns typically involve unauthorized access and data leakage.
Recommended steps:
- Enable encryption at rest for stored data.
- Use HTTPS to enforce encryption in transit.
- Apply strict IAM policies using least privilege access.
- Enable multi-factor authentication for administrative users.
- Activate logging and auditing to track access.
- Configure lifecycle policies and versioning for backup protection.
These measures protect confidentiality, integrity, and accountability of stored data.
3. A web application deployed on Kubernetes shows slow response times during peak hours. How would you approach this problem?
Performance issues during peak hours often indicate resource constraints or scaling limitations.
A structured approach:
- Check CPU and memory utilization of pods.
- Verify Horizontal Pod Autoscaler configuration.
- Inspect request and limit settings for containers.
- Analyze database performance and connection pool size.
- Review network latency between services.
- Use distributed tracing to identify slow services.
- Ensure readiness and liveness probes are correctly configured.
Example: If CPU consistently exceeds 80 percent without scaling, the autoscaler thresholds may need adjustment.
4. Your cloud-hosted application is running in a single region. Management wants higher resilience against regional outages. What architecture changes would you propose?
Single-region deployment increases outage risk.
Proposed improvements:
- Deploy the application in a secondary region.
- Replicate databases using cross-region replication.
- Use object storage cross-region replication.
- Implement global DNS routing with health checks.
- Design services to be stateless for easier failover.
- Use asynchronous data replication where acceptable.
This multi-region strategy reduces downtime and improves disaster recovery capability.
5. A financial services platform requires strict consistency for transactions but also needs global scalability. How would you design the database layer?
This requires balancing consistency, performance, and geographic distribution.
Design considerations:
- Use a strongly consistent relational database for transaction processing.
- Deploy primary database in one region with read replicas globally.
- Use synchronous replication within region and asynchronous cross-region replication.
- Implement database sharding if workload increases significantly.
- Use caching carefully without violating transactional integrity.
- Apply strict IAM and encryption policies for compliance.
Example: Core transaction writes can go to a primary RDS instance, while read-heavy reporting queries use replicas in different regions.
This design ensures transactional integrity while maintaining performance and availability at scale.
Cloud Computing MCQ
Preparing for objective-based rounds is just as important as mastering theoretical concepts. Cloud computing MCQs help you quickly test your understanding of core topics like service models, deployment types, security, and scalability.
Practicing multiple-choice questions improves speed, accuracy, and conceptual clarity before interviews. You can regularly practice structured cloud computing MCQs on PlacementPreparation.io to strengthen your preparation and perform confidently in written tests.
Final words
Cloud computing interviews test both your conceptual clarity and practical understanding of modern cloud services. Preparing systematically with structured questions and clear explanations helps build confidence across fresher, intermediate, and experienced levels.
Focus on understanding core concepts rather than memorizing answers. With consistent practice and revision, you can confidently handle cloud computing interview rounds.
FAQs
The most common interview questions for cloud computing focus on service models, deployment types, virtualization, scalability, security practices, and real-world cloud architecture scenarios that test conceptual clarity and practical understanding.
The best way to practice is by revising core concepts, solving structured interview questions, attempting MCQs, and reviewing scenario-based problems regularly to strengthen both theoretical and practical understanding.
You should choose based on career goals, industry demand, and personal interest. AWS is widely adopted, Azure is popular in enterprise environments, and Google Cloud excels in data and analytics services.
Freshers often give memorized definitions, lack structured explanations, ignore real-world examples, and fail to explain concepts clearly, which reduces their confidence and interview performance.
With consistent study and practice, a strong foundation in cloud computing can typically be built within one to two months, depending on prior technical knowledge and dedication.
Placement Preparation provides structured cloud computing interview questions, MCQs, and concept-based blogs to help students revise effectively, build confidence, and prepare systematically for technical placement interviews.


Aarthy is a passionate technical writer with diverse experience in web development, Web 3.0, AI, ML, and technical documentation. She has won over six national-level hackathons and blogathons. Additionally, she mentors students across communities, simplifying complex tech concepts for learners.


Aarthy is a passionate technical writer with diverse experience in web development, Web 3.0, AI, ML, and technical documentation. She has won over six national-level hackathons and blogathons. Additionally, she mentors students across communities, simplifying complex tech concepts for learners.
Related Posts

Top Prompt Engineering Interview Questions for Freshers
Prompt engineering is now a practical AI skill for freshers entering software, data, content, product, marketing, and automation roles. Reports show …


Warning: Undefined variable $post_id in /var/www/wordpress/wp-content/themes/placementpreparation/template-parts/popup-zenlite.php on line 1050
so far feels like...
