Hashing Algorithm in Data Structure

How do login systems verify usernames and passwords instantly? How do databases retrieve specific records without scanning millions of entries? How do modern applications avoid slow linear searches when handling large datasets?
The answer lies in hashing, a technique that enables fast data retrieval by mapping keys directly to storage locations using hash functions. Instead of searching through all data, hashing allows systems to access information almost instantly.
In this article, you will learn what hashing is, how hash tables work, how collisions are handled, the time complexity of hashing operations, and how hashing is implemented in real programs.
What is Hashing in Data Structures?
Hashing is a technique used in data structures to map keys to specific positions in a table using a hash function, allowing fast data storage and retrieval.
Instead of searching through all elements, hashing directly calculates the storage location, making operations much faster.
Simple flow:
Key → Hash Function → Index → Hash Table
Example:
Student ID → apply hash function → get index → store student record
For example, if the student ID is 123 and the hash function is ID % 10, the index becomes 3, and the data is stored at position 3.
Components of Hashing
Hashing works through several important components that together enable fast data storage and retrieval. Understanding these components helps in clearly understanding how hash tables function.
| Component | Meaning |
| Key | Input value used to generate an index |
| Hash Function | Converts key into an index value |
| Hash Table | Data structure that stores values |
| Bucket | Memory location where data is stored |
| Collision | Situation when multiple keys map to same index |
What is a Hash Function?
A hash function is a function that takes a key as input and converts it into an index position in a hash table. This index determines where the data will be stored or retrieved from.
A good hash function should have the following properties:
- Deterministic: The same key should always produce the same hash value.
- Fast computation: The function should generate the index quickly to maintain performance.
- Uniform distribution: Keys should be distributed evenly across the table to avoid clustering.
- Minimizes collisions: The function should reduce the chances of multiple keys mapping to the same index.
Example:
Key = 123
Hash function = key % 10
Hash value = 123 % 10 = 3
So, the data associated with key 123 will be stored at index 3 in the hash table.
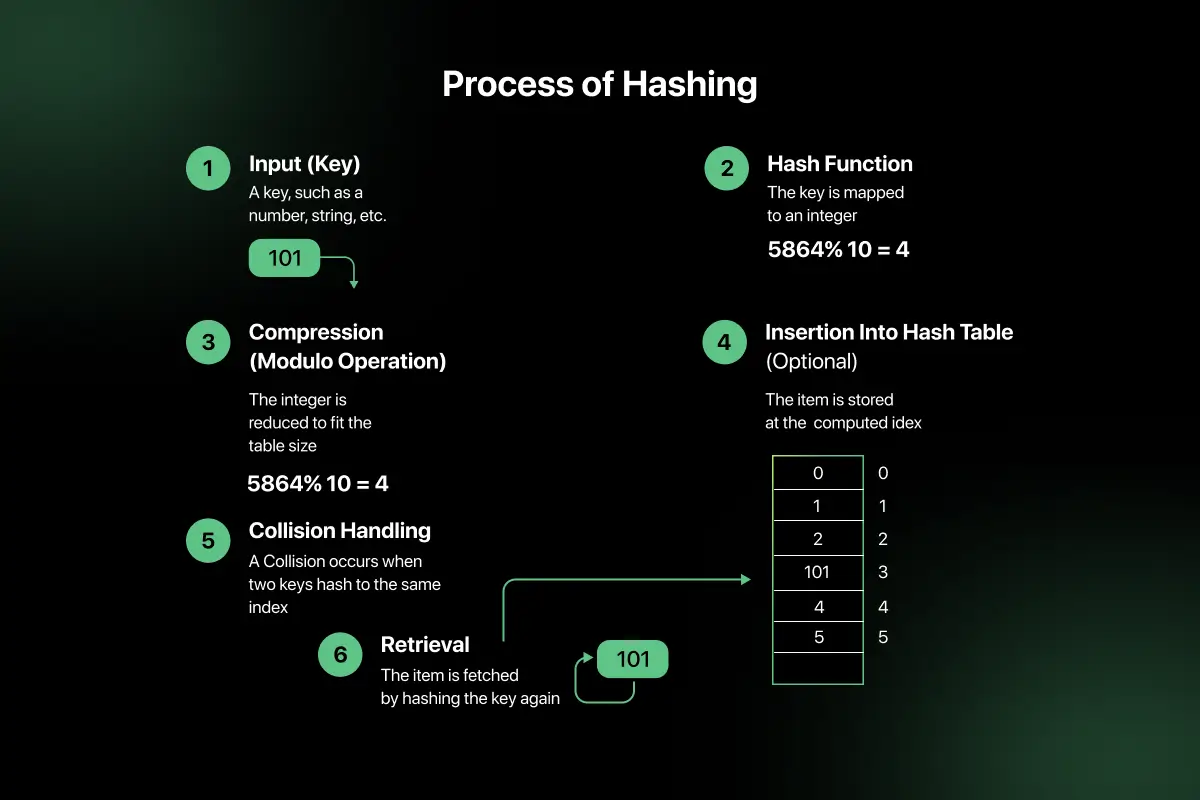
How Hashing Works (Step Process)
Hashing works by converting a key into a storage location using a hash function. This allows data to be stored and retrieved quickly without searching through all elements.
Step-by-step process:
- Step 1 → Take key: Identify the key that needs to be stored or searched.
- Step 2 → Apply hash function: Apply a hash function to convert the key into a numeric value.
- Step 3 → Generate index: The hash function produces an index that represents the storage position in the hash table.
- Step 4 → Store data: The data is stored at the calculated index for fast retrieval.
Example:
Key = 42
Hash function = key % 10
Hash value = 42 % 10 = 2
So, the data associated with key 42 will be stored at index 2 in the hash table.
Types of Hashing Techniques
Different hashing techniques are used to convert keys into index values efficiently. The goal is to distribute data uniformly across the hash table to reduce collisions.
1. Division Method
The division method is the simplest and most commonly used hashing technique. It uses the remainder of the key divided by the table size.
Formula:
Index = key % table size
Example:
37 % 10 = 7
So, the key 37 will be stored at index 7.
2. Multiplication Method
In this method, the key is multiplied by a constant value (usually between 0 and 1), and the fractional part is used to generate the index.
Process:
- Multiply the key with a constant.
- Extract the fractional part.
- Multiply by table size to get the index.
This method helps in achieving better distribution compared to simple division.
3. Mid Square Method
In this method, the key is squared and the middle digits of the result are used as the index.
Example:
25² = 625
Taking the middle digit gives index 2.
This method works well when keys are small and helps distribute values more evenly.
4. Folding Method
In the folding method, the key is divided into parts and then the parts are added together to generate the index.
Example:
Key = 12345
Split into parts:
12 + 34 + 5 = 51
The result can then be reduced further using modulo if needed.
This method is useful when dealing with large keys such as phone numbers or account numbers.
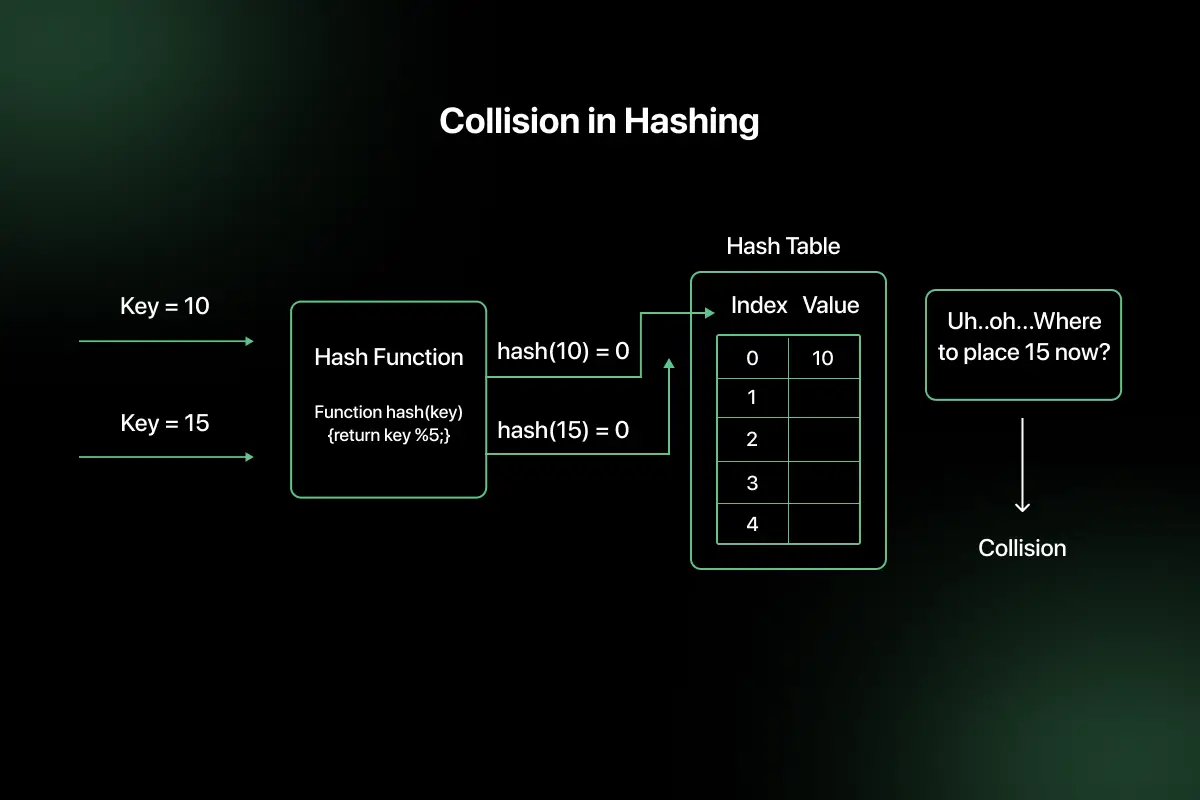
What is Collision in Hashing?
A collision in hashing occurs when two or more different keys produce the same index value after applying the hash function. Since the hash table has limited space, collisions are unavoidable in most practical implementations.
Example:
Key = 15 → Hash = 15 % 10 = 5
Key = 25 → Hash = 25 % 10 = 5
Both keys map to index 5, which creates a collision.
Because collisions cannot always be avoided, techniques such as separate chaining and open addressing are used to store multiple values at the same index efficiently.
Collision Resolution Techniques
Since collisions cannot be completely avoided, special techniques are used to handle situations where multiple keys map to the same index. These methods ensure that data can still be stored and retrieved efficiently.
1. Separate Chaining
Separate chaining resolves collisions by storing multiple elements at the same index using a linked list (or similar structure). When a collision occurs, the new element is simply added to the list at that index.
Example:
Index 5:
15 → 25 → 35
Here, all keys that hash to index 5 are stored in a chain, allowing multiple values to share the same bucket.
2. Open Addressing
Open addressing resolves collisions by finding another empty slot in the hash table instead of storing multiple values at the same index.
Common open addressing techniques include:
- Linear Probing: Searches the next available slot sequentially.
- Quadratic Probing: Searches slots using quadratic intervals to reduce clustering.
- Double Hashing: Uses a second hash function to determine the next position.
These techniques help maintain fast access even when collisions occur.
Time Complexity of Hashing
| Operation | Average | Worst |
| Search | O(1) | O(n) |
| Insert | O(1) | O(n) |
| Delete | O(1) | O(n) |
The worst case happens when many collisions occur.
Hashing Implementation Examples
Understanding hashing becomes easier when you see how it is implemented in code. Below are two simple and practical examples that show both the basic hashing logic and real-world usage.
1. Simple Hash Table Using Modulo Method
This example shows how a basic hash table works by storing numbers using the formula:
index = key % size
Here, the hash table is represented using an array. The key is converted into an index, and the value is stored at that position.
Python Code
# Simple hash table using the modulo method
size = 10
hash_table = [None] * size
def insert(key):
index = key % size
hash_table[index] = key
print(f”Inserted {key} at index {index}”)
def display():
print(“\nHash Table:”)
for i, value in enumerate(hash_table):
print(f”Index {i}: {value}”)
# Example usage
insert(15)
insert(22)
insert(37)
insert(42)
display()
Output Explanation
- For 15, index = 15 % 10 = 5
- For 22, index = 22 % 10 = 2
- For 37, index = 37 % 10 = 7
- For 42, index = 42 % 10 = 2
This shows that both 22 and 42 map to index 2, which creates a collision. In this simple version, the new value overwrites the old one. This example is useful for understanding the core hashing idea, but real implementations handle collisions properly.
2. HashMap Example to Store Student Marks
This is a more practical example using Python’s built-in dictionary, which works like a hash map. It allows fast insertion, search, and deletion using keys.
Python Code
# HashMap example using Python dictionary
student_marks = {}
# Insert key-value pairs
student_marks[“Aisha”] = 85
student_marks[“Rahul”] = 92
student_marks[“Meena”] = 78
print(“After insertion:”)
print(student_marks)
# Search for a key
name = “Rahul”
if name in student_marks:
print(f”\n{name}’s marks: {student_marks[name]}”)
else:
print(f”\n{name} not found”)
# Delete a key
del student_marks[“Meena”]
print(“\nAfter deletion:”)
print(student_marks)
Output Explanation
- Insertion: Stores student names as keys and marks as values.
- Search: Quickly checks whether a student name exists and returns the value.
- Deletion: Removes the key-value pair from the hash map.
This is the most common real-world use of hashing in programming because it provides very fast average-time operations for storing and retrieving data.
Hashing vs Other Data Structures
| Data Structure | Search Time |
| Array | O(n) |
| BST | O(log n) |
| Hash Table | O(1) |
Hashing fastest for lookup.
Advantages and Limitations of Hashing
Advantages
- Very fast lookup: Hashing allows quick data retrieval without scanning all elements.
- O(1) average search: Most operations like search, insert, and delete work in constant time on average.
- Used in databases: Hashing is widely used for indexing and fast record retrieval.
- Efficient indexing: Helps map large datasets to manageable storage locations.
- Used in caching: Enables fast access to frequently used data in systems like web caching.
Limitations
- Collisions unavoidable: Multiple keys can map to the same index, requiring collision handling techniques.
- Requires extra memory: Hash tables may need additional space for better performance.
- No ordering of data: Unlike trees, hashing does not maintain sorted order.
- Poor hash function reduces efficiency: Bad hash functions can increase collisions and reduce performance.
- Worst case O(n): When collisions are excessive, operations may degrade to linear time.
Real World Use Cases of Hashing
- Databases: Hashing is used for indexing to quickly locate records without scanning entire tables.
- Cybersecurity: Passwords are stored using hashing to protect sensitive user information.
- Caching systems: Hashing helps quickly retrieve frequently accessed data in applications and browsers.
- Artificial Intelligence: Used for feature mapping and fast data lookup in large datasets.
- Blockchain: Cryptographic hashing ensures data integrity and secure transaction verification.
- Networking: Hashing helps in routing and load balancing across servers.
Hashing in Technical Interviews
Hashing is a frequently tested topic in technical interviews because it helps evaluate a candidate’s understanding of data structures, optimization, and problem-solving ability.
Common Interview Questions
- Companies often ask questions such as:
- What is hashing and how does it work?
- How are collisions resolved in hash tables?
- Why is HashMap O(1) on average?
- How would you design a simple hash table?
- Compare hashing with Binary Search Trees (BST).
Preparation Tips
To prepare effectively for hashing questions:
- Practice hashing problems: Solve problems involving hash maps and hash sets.
- Learn collision techniques: Understand chaining and open addressing methods.
- Study time complexity: Know average and worst-case complexities.
- Practice MCQs: Strengthen theoretical understanding of hashing concepts.
- Practice company-specific questions: Focus on interview questions asked by major IT companies.
For structured preparation, you can practice DSA problems, hashing questions, and MCQ tests on PlacementPreparation.io and explore GUVI courses to strengthen your interview readiness.
Final Words
Hashing is a powerful technique that enables fast data storage and retrieval, making it an essential concept in data structures. Its ability to provide near constant-time operations makes it widely used in databases, caching systems, and real-world applications.
It is also an important topic in technical interviews where understanding hash functions, collisions, and complexity can improve problem-solving performance. Regular practice of hashing problems and DSA concepts helps build strong coding and optimization skills.
FAQs
Hashing is a technique used to map keys to index positions using a hash function, allowing fast data storage and retrieval.
A hash function converts a key into an index value used to store or retrieve data in a hash table.
HashMap operations are O(1) on average because hashing allows direct access to data using computed indices.
Load factor is the ratio of stored elements to table size, used to measure hash table efficiency and decide resizing.
Yes, hashing is commonly asked in technical interviews because it tests understanding of data structures and optimization techniques.
HashMap stores key-value pairs with fast lookup, while arrays store indexed elements and require sequential search for values.


Aarthy is a passionate technical writer with diverse experience in web development, Web 3.0, AI, ML, and technical documentation. She has won over six national-level hackathons and blogathons. Additionally, she mentors students across communities, simplifying complex tech concepts for learners.


Aarthy is a passionate technical writer with diverse experience in web development, Web 3.0, AI, ML, and technical documentation. She has won over six national-level hackathons and blogathons. Additionally, she mentors students across communities, simplifying complex tech concepts for learners.
Related Posts

Searching Algorithm in Data Structure
Searching is one of the most fundamental operations in computer science because almost every application involves finding specific data efficiently. …


Warning: Undefined variable $post_id in /var/www/wordpress/wp-content/themes/placementpreparation/template-parts/popup-zenlite.php on line 1050
so far feels like...
