System Design Interview Questions and Answers

Are you preparing for system design interviews and wondering what kind of architectural questions you might face?
System design interviews test your ability to think at scale, make trade-offs, and design reliable, distributed systems that handle real-world traffic and failures.
This guide on system design interview questions and answers covers core concepts, intermediate-level component design, and advanced large-scale architecture discussions to help you build structured thinking and confidently approach system design rounds.
System Design Interview Questions for Freshers
1. What is system design, and why is it important in software engineering?
System design is the process of defining the architecture, components, data flow, and interactions required to build a scalable and reliable software system.
It involves decisions about:
- Backend services
- Databases
- APIs
- Scaling strategy
- Fault tolerance
- Data storage
- Communication between components
System design is important because:
- It ensures scalability as users grow.
- It prevents performance bottlenecks.
- It improves maintainability.
- It reduces system failure risks.
- It aligns technical architecture with business requirements.
For example, designing a simple e-commerce app without considering scaling could cause the system to crash during high-traffic sales events.
2. What is scalability in system design?
Scalability refers to a system’s ability to handle increasing load without performance degradation.
A scalable system can:
- Handle more users
- Process more requests
- Store more data
- Maintain stable response time
Example:
If a web server handles 1,000 requests per second today, a scalable design allows it to handle 100,000 requests per second tomorrow by adding resources.
Scalability is a core requirement in modern distributed systems.
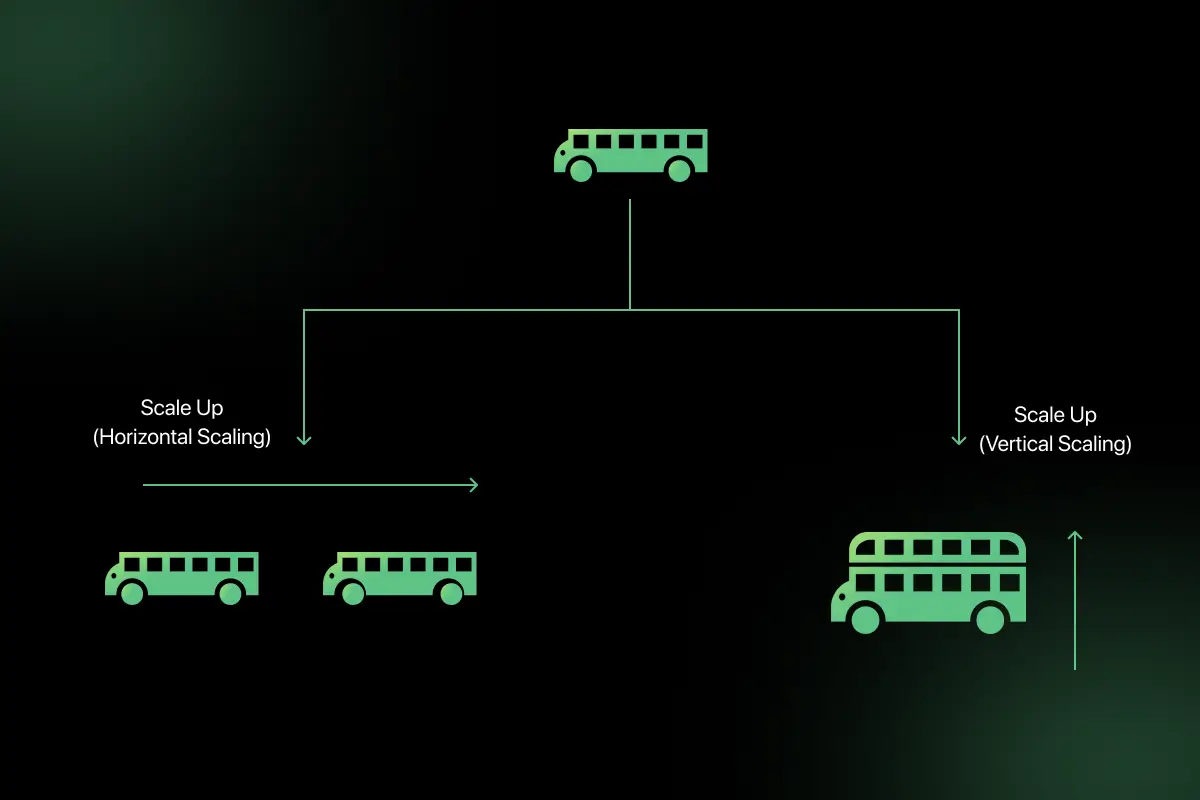
3. What is the difference between vertical scaling and horizontal scaling?
| Feature | Vertical Scaling | Horizontal Scaling |
| Definition | Increase power of a single machine | Add more machines |
| Example | Upgrade CPU/RAM | Add more servers |
| Complexity | Simple | More complex |
| Scalability Limit | Hardware limit | Practically unlimited |
| Fault Tolerance | Low | High |
Vertical scaling means upgrading an existing server, while horizontal scaling means distributing load across multiple servers.
For example, increasing RAM from 16GB to 64GB is vertical scaling. Adding 5 more servers behind a load balancer is horizontal scaling.
4. What is high availability?
High availability (HA) refers to designing systems to minimize downtime and ensure continuous operation.
It is achieved using:
- Redundant servers
- Load balancing
- Failover mechanisms
- Multi-region deployment
- Health checks
Example:
If one server fails, traffic automatically shifts to another healthy server without user impact.
High availability is typically measured as uptime percentage (e.g., 99.99%).
5. What is load balancing?
Load balancing distributes incoming traffic across multiple servers to ensure optimal resource utilization and prevent overload.
It improves:
- Performance
- Reliability
- Scalability
Common algorithms:
- Round Robin
- Least Connections
- IP Hash
Example architecture:
Client → Load Balancer → Multiple Application Servers
Load balancers can operate at:
Layer 4 (Transport level)
Layer 7 (Application level)
Load balancing prevents a single server from becoming a bottleneck.
6. What is caching, and why is it used?
Caching stores frequently accessed data in fast storage to reduce response time and database load.
It is used to:
- Improve performance
- Reduce database queries
- Reduce latency
- Lower infrastructure cost
Example:
Instead of querying a database every time for product details, store results in Redis.
Pseudo flow:
if (data in cache):
return cached_data
else:
fetch from database
store in cache
return data
Caching is widely used in high-traffic systems like e-commerce and social media platforms.

7. What is database sharding?
Database sharding is the process of splitting a large database into smaller, independent pieces called shards.
Each shard contains a subset of data.
Example:
Users table split based on user ID:
- Shard 1 → Users with ID 1–1,000,000
- Shard 2 → Users with ID 1,000,001–2,000,000
Benefits:
- Improves scalability
- Reduces query load
- Enables horizontal scaling
Sharding is useful when a single database cannot handle growing data volume.
8. What is replication in databases?
Replication is the process of copying data from one database server to another.
Types:
- Master-Slave replication
- Multi-Master replication
Benefits:
- High availability
- Fault tolerance
- Improved read performance
Example:
- Writes go to primary database.
- Reads are distributed across replicas.
Replication ensures system reliability and load distribution.
9. What is CAP theorem?
CAP theorem states that a distributed system can only guarantee two of the following three properties:
- Consistency – All nodes see the same data at the same time.
- Availability – Every request receives a response.
- Partition Tolerance – System continues operating despite network failures.
You cannot guarantee all three simultaneously.
For example:
- Banking systems prioritize Consistency and Partition tolerance.
- Social media systems may prioritize Availability and Partition tolerance.
CAP theorem helps architects make trade-off decisions.
10. What is eventual consistency?
Eventual consistency is a consistency model where updates to data will propagate to all nodes eventually, but not immediately.
This means:
- Some nodes may temporarily have stale data.
- After some time, all nodes converge to the same state.
Example:
- When you post on social media, it may not instantly appear for all users globally, but it eventually syncs.
- Eventual consistency improves availability and scalability in distributed systems.
11. What is monolithic architecture?
Monolithic architecture is a software design approach where the entire application is built as a single unified codebase and deployed as one unit. All components, such asthe user interface, business logic, and database access are tightly integrated and run within the same process.
In a monolithic system, if a small feature needs modification, the entire application typically needs to be rebuilt and redeployed. This approach is simpler to develop initially and is suitable for small applications.
However, as the system grows, it becomes harder to scale, maintain, and deploy independently. For example, early-stage startups often begin with monolithic architecture due to its simplicity.
12. What is microservices architecture?
Microservices architecture is a design approach where an application is divided into small, independent services that communicate with each other over a network. Each service is responsible for a specific business capability and can be developed, deployed, and scaled independently.
For example, in an e-commerce application, user management, payment processing, and product catalog may each run as separate services. Microservices improve scalability, flexibility, and fault isolation. However, they introduce complexity in service communication, deployment, monitoring, and data consistency.
13. Compare monolithic and microservices architectures.
| Feature | Monolithic Architecture | Microservices Architecture |
| Structure | Single unified codebase | Multiple independent services |
| Deployment | Entire app deployed together | Services deployed independently |
| Scalability | Hard to scale specific components | Individual services can scale |
| Fault Isolation | Failure affects whole system | Failure isolated to one service |
| Complexity | Simpler initially | More complex infrastructure |
| Maintenance | Harder as system grows | Easier modular maintenance |
Monolithic architecture is easier to start with, while microservices are better suited for large-scale distributed systems requiring independent scaling and flexibility.
14. What is a reverse proxy?
A reverse proxy is a server that sits between clients and backend servers, forwarding client requests to appropriate internal servers and returning responses back to clients.
Unlike a forward proxy (which represents clients), a reverse proxy represents backend servers. It provides several benefits:
- Load balancing
- SSL termination
- Security filtering
- Caching
- Hiding internal server details
For example, when a client requests a website, the reverse proxy routes the request to one of several backend servers without exposing internal infrastructure. Common reverse proxies include NGINX and HAProxy.
15. What is an API gateway?
An API gateway is a centralized entry point for managing and routing requests to multiple backend services in a distributed system. It is commonly used in microservices architecture.
The API gateway handles:
- Authentication and authorization
- Request routing
- Rate limiting
- Logging and monitoring
- Request aggregation
For example, instead of a mobile app calling multiple microservices directly, it calls the API gateway, which internally communicates with appropriate services. This simplifies client communication and centralizes cross-cutting concerns.
16. What is the difference between SQL and NoSQL databases?
| Feature | SQL Databases | NoSQL Databases |
| Structure | Structured tables | Flexible schemas |
| Schema | Fixed schema | Dynamic schema |
| Scalability | Vertical scaling | Horizontal scaling |
| Data Model | Relational | Document, key-value, graph, column |
| Example | MySQL, PostgreSQL | MongoDB, Cassandra |
SQL databases are suitable for structured data and strong consistency requirements, such as banking systems. NoSQL databases are ideal for large-scale distributed systems with flexible data models and high scalability needs.
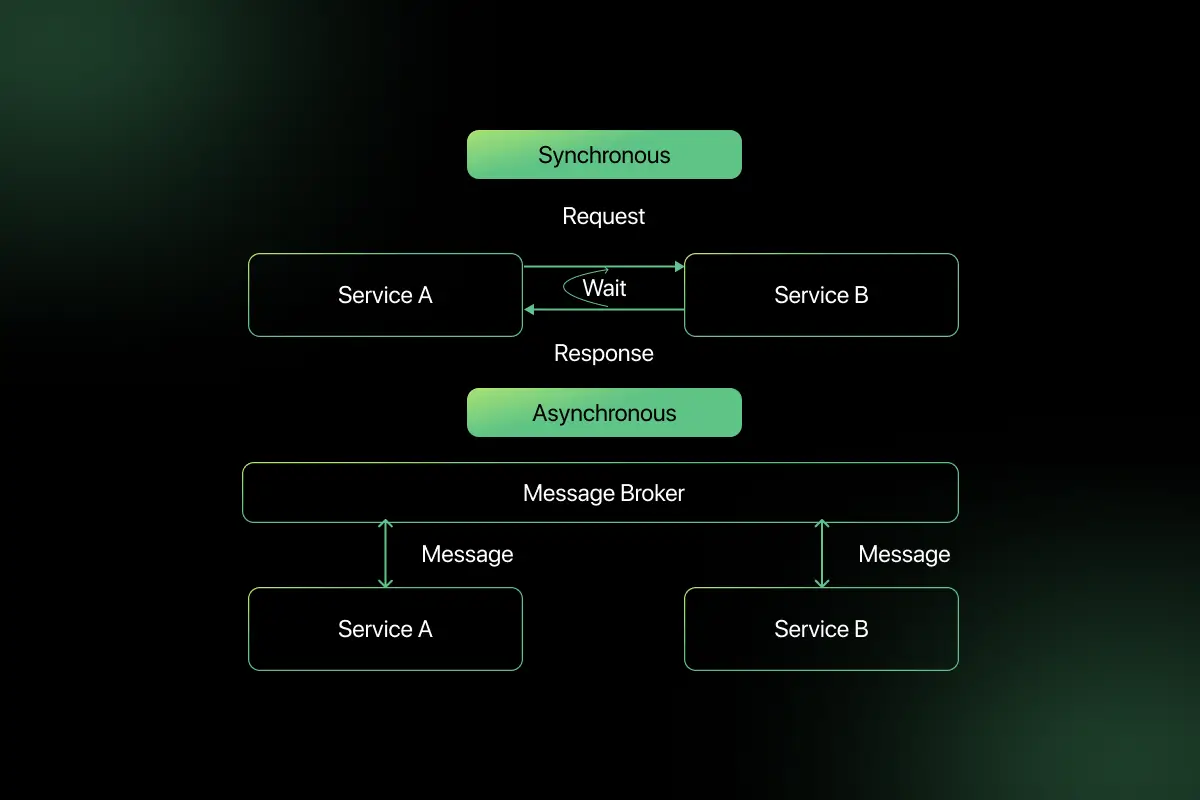
17. What is the difference between synchronous and asynchronous communication?
| Feature | Synchronous Communication | Asynchronous Communication |
| Execution | Waits for response | Does not wait for response |
| Dependency | Blocking | Non-blocking |
| Performance | Slower under load | More scalable |
| Example | REST API call | Message queue event |
In synchronous communication, a service waits for a response before proceeding. In asynchronous communication, a service sends a request and continues execution without waiting, often using message queues like Kafka or RabbitMQ. Asynchronous systems improve scalability and resilience.
18. What is latency vs throughput?
Latency is the time taken for a request to travel from client to server and receive a response. It is typically measured in milliseconds.
Throughput refers to the number of requests or transactions a system can process per unit time, usually measured in requests per second.
For example, a system may have low latency (fast response per request) but low throughput (limited total capacity). A well-designed system aims to optimize both depending on use case requirements.
19. What is fault tolerance?
Fault tolerance is the ability of a system to continue operating correctly even when one or more components fail.
It is achieved through:
- Redundant servers
- Data replication
- Failover mechanisms
- Health checks
- Auto-recovery systems
For example, if one database server crashes, a replicated backup server automatically takes over without disrupting users. Fault tolerance improves system reliability and uptime.
20. What is a CDN and why is it used?
A CDN (Content Delivery Network) is a geographically distributed network of servers that cache and deliver content closer to users.
When a user requests content:
- The request is routed to the nearest CDN edge server.
- Cached content is served quickly.
- If not cached, it fetches from origin server.
CDNs reduce latency, improve performance, reduce server load, and enhance availability. They are widely used for delivering images, videos, scripts, and static website assets globally.
System Design Interview Questions for Intermediate
1. How would you design a URL shortening service?
A URL shortening service converts long URLs into shorter, unique links and redirects users to the original URL when accessed.
Core components:
- API layer to accept long URLs
- Unique ID generator
- Database to store mapping (short → long URL)
- Redirection service
- Caching layer for frequently accessed links
Design steps:
- Generate a unique ID using Base62 encoding.
- Store mapping in database.
- Return shortened URL.
- On access, look up ID and redirect (HTTP 302).
Example pseudocode:
- function shortenURL(longURL):
- id = generateUniqueID()
- shortURL = base62(id)
- store(shortURL, longURL)
- return shortURL
To scale:
- Use database sharding.
- Cache popular URLs.
- Add rate limiting.
- Use CDN for faster redirection.
2. How do you design a scalable web application?
Designing a scalable web application requires separating components and enabling horizontal scaling.
Architecture:
- Client→ Load Balancer → Application Servers
- Application Servers → Database
- Caching layer (Redis)
- CDN for static assets
Key strategies:
- Stateless application servers.
- Horizontal scaling using auto-scaling groups.
- Database replication for read scalability.
- Caching to reduce database load.
- Asynchronous processing using message queues.
This architecture ensures the system handles increasing traffic without degradation.
3. How does database indexing improve performance?
Database indexing improves performance by creating a data structure that allows faster lookups.
Without index:
- Database scans entire table (O(n)).
- With index:
- Uses B-Tree or Hash index (O(log n)).
Example:
- If a user table has 10 million rows and a query searches by email, indexing the email column significantly reduces lookup time.
- However, indexes increase storage and slow down write operations. Therefore, indexing should be applied selectively to frequently queried columns.
4. How do you design a rate limiter?
A rate limiter controls how many requests a user can make within a defined time period.
Common algorithms:
- Fixed Window Counter
- Sliding Window
- Token Bucket
- Leaky Bucket
Example: Token Bucket pseudocode
if tokens > 0:
allow_request()
tokens -= 1
else:
reject_request()
Implementation considerations:
- Store counters in Redis for distributed systems.
- Use IP or user ID for tracking.
- Return HTTP 429 when limit exceeded.
Rate limiting prevents abuse and protects system resources.
5. What is the difference between strong consistency and eventual consistency?
| Feature | Strong Consistency | Eventual Consistency |
| Data Accuracy | Immediate consistency | Eventually consistent |
| Read Behavior | Always latest data | May return stale data |
| Availability | Lower during partition | Higher availability |
| Use Case | Banking systems | Social media feeds |
Strong consistency ensures all nodes reflect the same data immediately. Eventual consistency allows temporary inconsistencies but improves scalability and availability.
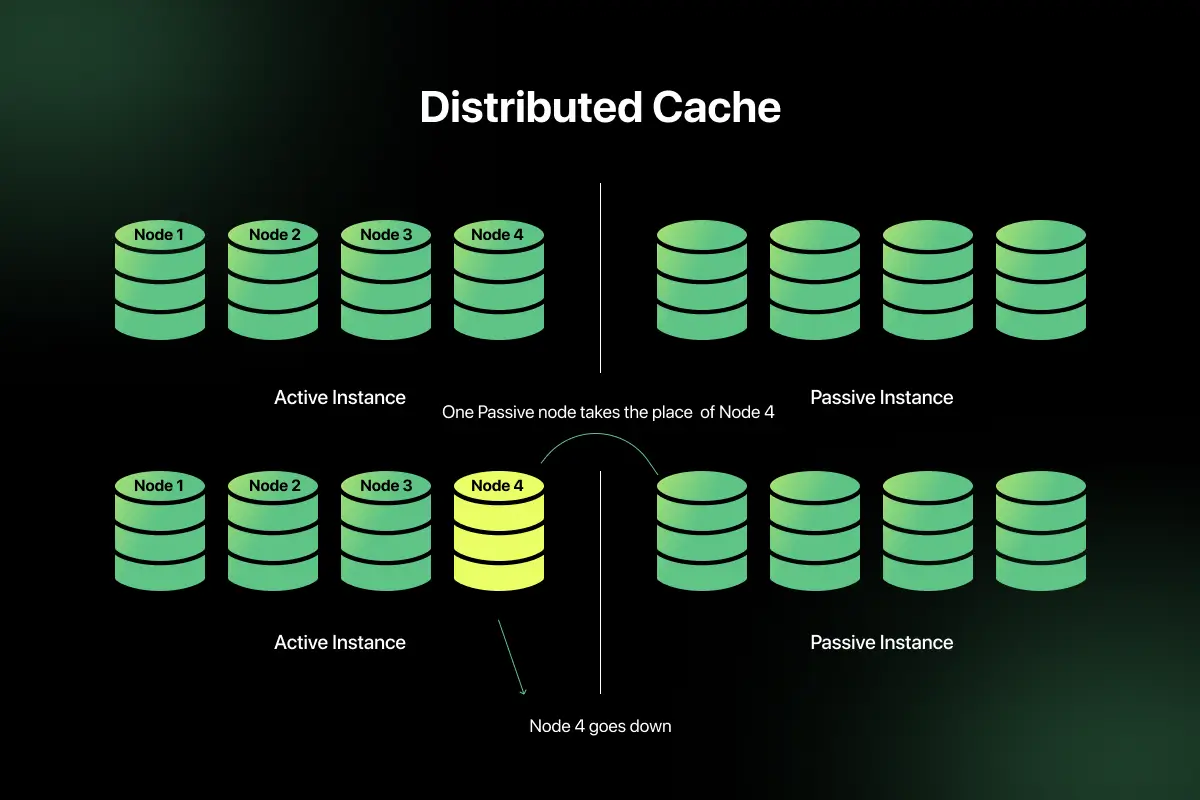
6. How would you design a distributed cache?
A distributed cache stores frequently accessed data across multiple nodes.
Design components:
- Cache nodes (Redis cluster)
- Consistent hashing for data distribution
- Replication for fault tolerance
- Eviction policies (LRU, LFU)
Flow:
- Check cache.
- If miss, fetch from database.
- Store result in cache.
- Return data.
Challenges include cache invalidation and maintaining consistency between cache and database.
7. What are different database partitioning strategies?
Database partitioning splits data into smaller segments.
Types:
- Horizontal Partitioning (Sharding) – Rows split across servers.
- Vertical Partitioning – Columns split across tables.
- Range Partitioning – Based on value ranges.
- Hash Partitioning – Based on hash function.
- List Partitioning – Based on specific values.
For example, user data can be partitioned by region to improve performance and locality.
Partitioning improves scalability and query efficiency.
8. How do you design a notification system?
A notification system delivers messages such as emails, SMS, or push notifications.
Architecture:
- User triggers event.
- Event stored in message queue.
- Worker processes queue.
- Notification service sends message.
Components:
- API layer
- Message queue (Kafka, RabbitMQ)
- Notification workers
- Retry mechanism
- Logging and monitoring
Asynchronous processing ensures system scalability and reliability.
9. How would you design a logging system?
A logging system collects, stores, and analyzes application logs.
Architecture:
- Application servers generate logs.
- Logs sent to log collector.
- Centralized storage (Elasticsearch).
- Visualization tool (Kibana).
- Alerting system.
Key considerations:
- Structured logging (JSON).
- Log rotation.
- Log retention policy.
- High availability storage.
Centralized logging improves observability and debugging.
10. How do you design a file storage system?
A file storage system must support upload, storage, and retrieval of files.
Architecture:
- Upload API
- Storage layer (Object storage like S3)
- Metadata database
- CDN for file delivery
Design considerations:
- Use object storage for scalability.
- Store metadata separately.
- Enable file chunking for large uploads.
- Use replication for durability.
- Implement access control.
Example flow:
- User uploads file.
- File stored in object storage.
- Metadata stored in database.
- CDN serves file to users.
This ensures scalability, durability, and performance.
11. What is message queue, and when would you use it?
A message queue is a communication mechanism that allows services to exchange data asynchronously. Instead of directly calling another service and waiting for a response, a service publishes a message to a queue, and another service processes it independently.
You would use a message queue when:
- You want asynchronous processing.
- You need to decouple services.
- You want to handle traffic spikes smoothly.
- You need reliable event-driven architecture.
For example, in an e-commerce system, after placing an order, the order service publishes an event to a queue. Payment, inventory, and notification services consume the event independently. This improves scalability and fault isolation.
12. Compare REST and gRPC in distributed systems.
| Feature | REST | gRPC |
| Protocol | HTTP/1.1 | HTTP/2 |
| Data Format | JSON | Protocol Buffers (binary) |
| Performance | Moderate | High performance |
| Streaming | Limited | Supports streaming |
| Use Case | Public APIs | Internal microservices |
REST is widely used for public APIs due to simplicity and readability. gRPC is more efficient and suitable for internal service-to-service communication because it uses binary serialization and supports bidirectional streaming.
13. What is service discovery?
Service discovery is a mechanism that enables services in a distributed system to dynamically find and communicate with each other.
Instead of hardcoding IP addresses, services register themselves with a registry (e.g., Consul, Eureka, etcd). When a service needs to call another service, it queries the registry to get the current instance location.
Service discovery is essential in microservices environments where instances scale up or down dynamically.
14. What is circuit breaker pattern?
The circuit breaker pattern prevents a system from repeatedly trying to execute a failing operation, which could cause cascading failures.
It operates in three states:
- Closed (normal operation)
- Open (fail fast, do not call downstream service)
- Half-open (test if service has recovered)
For example, if a payment service is down, instead of continuously retrying and overloading the system, the circuit breaker stops calls temporarily and returns fallback responses.
This improves system resilience and stability.
15. What is idempotency in distributed systems?
Idempotency means that performing the same operation multiple times produces the same result as performing it once.
For example, if a payment request is retried due to a timeout, the system should not process the payment twice.
Implementation strategy:
- Use unique request identifiers.
- Store processed request IDs.
- Return the same response for duplicate requests.
Idempotency is critical in distributed systems where network failures can cause retries.
16. How do you choose between SQL and NoSQL for a new system?
Choosing between SQL and NoSQL depends on system requirements.
Use SQL when:
- Strong consistency is required.
- Data relationships are complex.
- Transactions are critical.
Use NoSQL when:
- Schema flexibility is required.
- High scalability is needed.
- Large volumes of unstructured data exist.
For example, a banking system prefers SQL for ACID transactions, while a social media feed system may use NoSQL for scalability.
17. How do you handle database migration in production?
Database migration in production must be handled carefully to avoid downtime.
Best practices:
- Use backward-compatible schema changes.
- Apply migrations in phases.
- Avoid dropping columns immediately.
- Use feature flags.
- Test migrations in staging.
- Use blue-green deployment strategy.
For example, add new columns first, update application code, then gradually remove old fields.
Proper migration planning prevents service disruption.
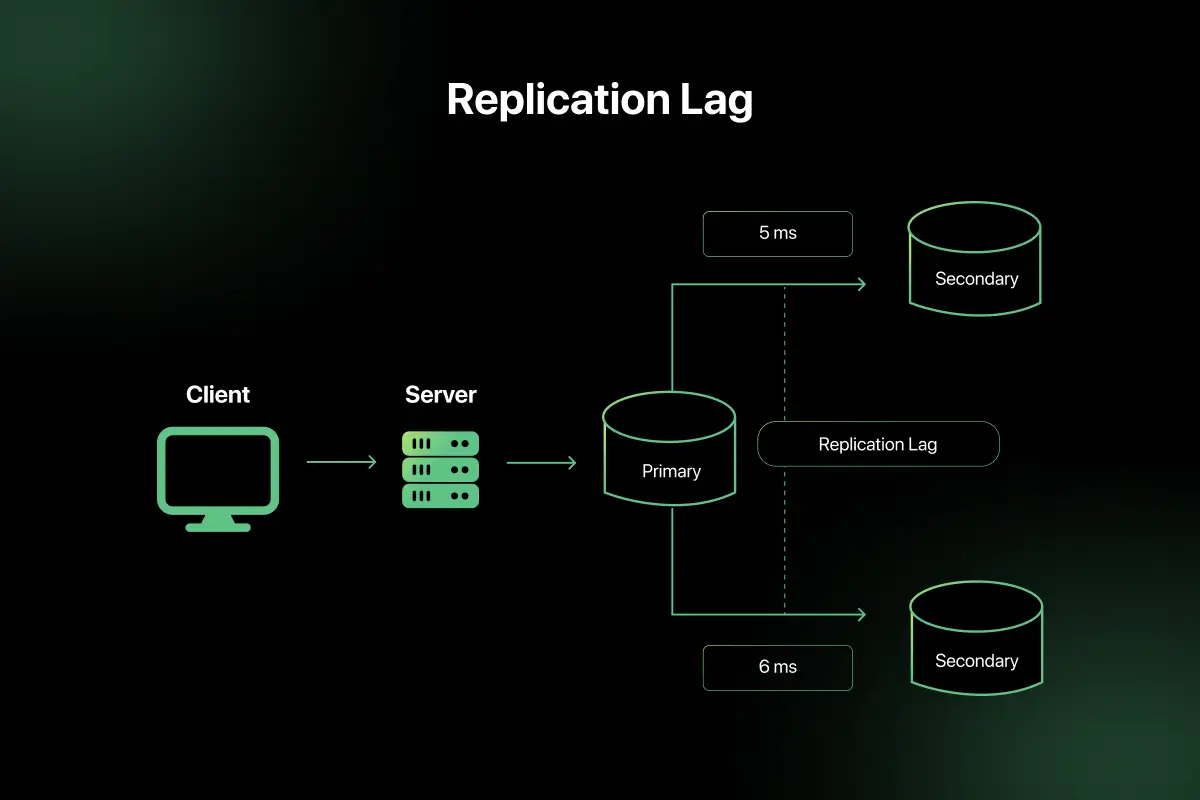
18. What is data replication lag?
Data replication lag occurs when replicas do not immediately reflect updates made to the primary database.
In master-replica systems:
- Writes occur on primary.
- Reads may occur on replicas.
- Replicas may temporarily return stale data.
Replication lag is measured in milliseconds or seconds and can impact systems requiring strong consistency.
Monitoring replication delay is critical in distributed databases.
19. What is backpressure in distributed systems?
Backpressure is a mechanism to prevent a fast producer from overwhelming a slower consumer in a distributed system.
If producers generate data faster than consumers can process it:
- Queues may overflow.
- System performance degrades.
- Failures may occur.
Solutions:
- Apply rate limiting.
- Use bounded queues.
- Implement flow control mechanisms.
- Scale consumers horizontally.
Backpressure ensures system stability under heavy load.
20. How would you design a simple chat application?
Design components:
- Client applications (web/mobile).
- API servers.
- WebSocket connections for real-time communication.
- Message queue for processing.
- Database for message storage.
- Presence service for online status.
Architecture flow:
- User sends message via WebSocket.
- Message stored in database.
- Message pushed to recipient.
- Offline messages retrieved later.
Scaling strategies:
- Use load balancer for API servers.
- Use distributed database.
- Partition users by region.
- Use CDN for media content.
A chat application requires low latency, real-time communication, and scalable storage.
System Design Interview Questions for Experienced
1. How would you design a scalable social media platform?
Designing a scalable social media platform requires handling massive user traffic, high write volume, and real-time feed updates.
High-level architecture includes:
- API layer behind load balancers
- Microservices (User service, Post service, Feed service)
- NoSQL database for posts
- SQL database for user data
- Distributed cache (Redis)
- CDN for images and media
- Message queue for asynchronous processing
Feed generation can be implemented using either:
- Fan-out on write (push model) for active users
- Fan-out on read (pull model) for large follower counts
Sharding by user ID ensures horizontal scalability. Replication and multi-region deployment ensure high availability.
2. How do you handle distributed transactions?
Distributed transactions involve multiple services or databases that must either all succeed or all fail. Traditional two-phase commit (2PC) can ensure atomicity but introduces latency and availability issues in distributed systems.
In modern architectures, distributed transactions are commonly handled using the Saga pattern. A saga breaks a large transaction into smaller local transactions, each with a compensating action in case of failure. Sagas can be orchestrated centrally or choreographed using events.
For example, in an e-commerce system, order creation, payment processing, and inventory update occur as separate steps. If payment fails, a compensating transaction cancels the order. This approach improves scalability and avoids locking resources across services.
3. How would you design YouTube or a video streaming service?
A video streaming system requires storage, encoding, distribution, and delivery optimization.
Core components:
- Video upload service
- Distributed object storage
- Encoding pipeline (transcoding to multiple resolutions)
- Metadata database
- CDN for global distribution
- Recommendation service
Flow:
- User uploads video.
- Video stored in distributed storage.
- Background workers transcode video.
- CDN caches content near users.
To scale:
- Use chunked uploads.
- Store metadata separately.
- Use consistent hashing for storage.
- Use CDN to reduce origin server load.
4. What is a consensus algorithm? Explain Raft or Paxos.
A consensus algorithm ensures that distributed nodes agree on a single value or system state despite failures.
Raft is a widely used consensus algorithm designed for understandability and reliability. It works through:
- Leader election
- Log replication
- Safety guarantees
In Raft:
- A leader node is elected.
- All write requests go through the leader.
- The leader replicates logs to followers.
- Once a majority acknowledges, the entry is committed.
This ensures consistency across distributed systems such as etcd or Kubernetes control planes. Consensus algorithms are essential in distributed databases and coordination systems.
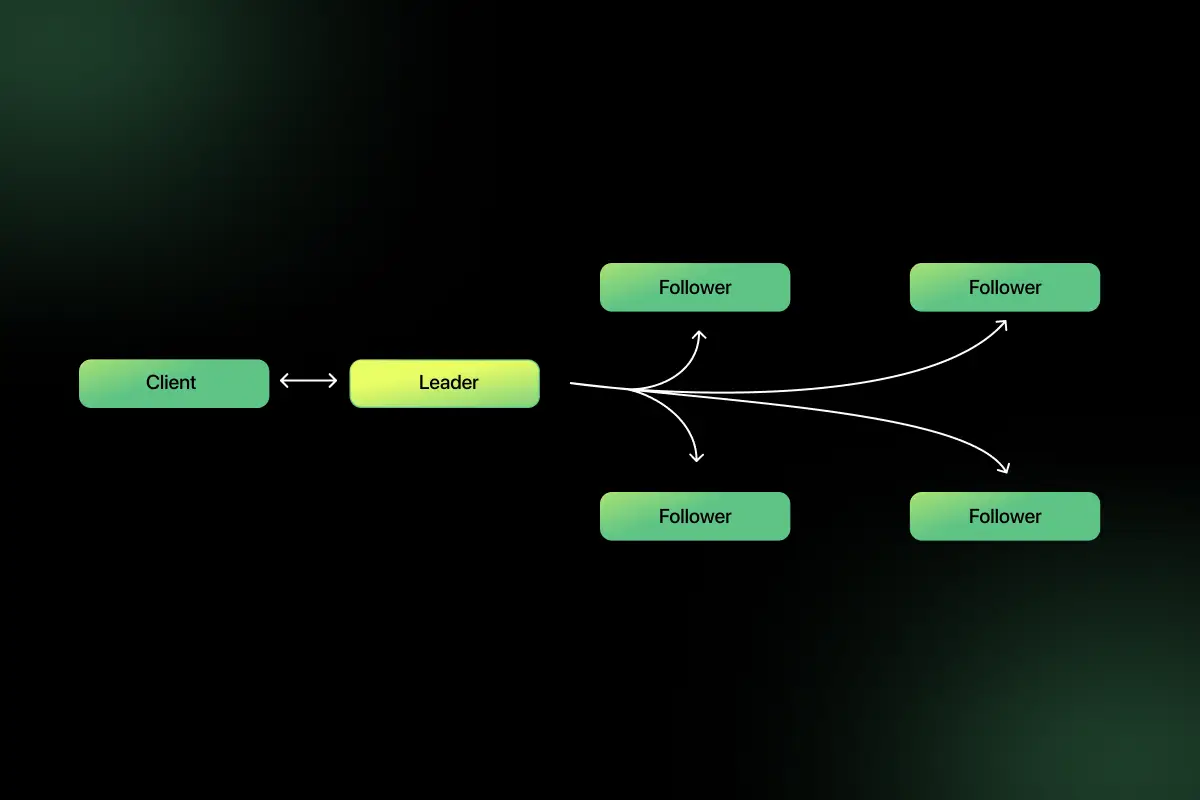
5. How would you design a distributed search engine?
A distributed search engine must support indexing, querying, and ranking.
Architecture includes:
- Web crawler
- Indexer service
- Distributed inverted index
- Query processing layer
- Ranking algorithm
- Cache layer
Data is partitioned across shards. Each shard maintains part of the index. Queries are broadcast to shards, results aggregated, and ranked.
Systems like Elasticsearch use this model. Replication ensures availability and fast query processing.
6. What is the eventual consistency trade-off in global systems?
Eventual consistency allows data updates to propagate asynchronously across distributed nodes. While this improves availability and performance, it introduces temporary inconsistencies.
In global systems, enforcing strong consistency across regions increases latency due to cross-region communication. Eventual consistency reduces latency but may allow stale reads.
For example, in social media platforms, a newly posted update may not instantly appear globally. This trade-off prioritizes availability and performance over immediate consistency.
Architects must evaluate whether the application requires immediate consistency or can tolerate temporary inconsistencies.
7. How would you design a ride-sharing system?
A ride-sharing system requires real-time location tracking and matching.
Components:
- User service
- Driver service
- Location tracking (GPS updates)
- Matching engine
- Pricing service
- Payment service
Flow:
- User requests ride.
- Matching service finds nearby drivers using geospatial indexing.
- Real-time updates via WebSockets.
- Payment processed after ride completion.
To scale:
- Partition drivers by geographic region.
- Use in-memory cache for location data.
- Use message queues for event handling.
- Deploy regionally to reduce latency.
8. How do you handle data partitioning at massive scale?
At massive scale, data must be partitioned across multiple machines to distribute load and storage.
Common strategies include:
- Hash-based partitioning
- Range-based partitioning
- Geographic partitioning
Consistent hashing is often used to evenly distribute keys across nodes while minimizing data movement when nodes are added or removed.
For example, in a distributed key-value store, user data may be partitioned based on user ID hash. Replication ensures durability, and rebalancing mechanisms maintain uniform distribution.
Proper partitioning avoids hotspots and improves system scalability.
9. How would you design a payment processing system?
A payment system requires reliability, security, and strong consistency.
Core components:
- API gateway
- Authentication service
- Transaction service
- Ledger database (strong consistency)
- Fraud detection service
- Message queue for asynchronous events
Design principles:
- Use idempotency keys for retries.
- Ensure ACID compliance.
- Encrypt sensitive data.
- Implement audit logging.
High availability and multi-region failover are critical to prevent downtime.
10. How do you design for disaster recovery?
Disaster recovery ensures system continuity during catastrophic failures.
Key strategies include:
- Multi-region deployment
- Automated backups
- Data replication
- Failover systems
- Regular disaster recovery testing
Recovery objectives include:
- RTO (Recovery Time Objective)
- RPO (Recovery Point Objective)
For example, deploying services in multiple regions with active-active replication ensures that if one region fails, traffic shifts automatically. Disaster recovery planning minimizes downtime and data loss.
11. How would you design a real-time messaging system like WhatsApp?
A messaging system requires low latency and high throughput.
Components:
- WebSocket servers
- Message queue
- Distributed database
- Presence service
- Media storage
Flow:
- User sends message via persistent connection.
- Message stored in database.
- If recipient online, push instantly.
- If offline, store for later delivery.
Scaling strategies:
- Partition users across servers.
- Use sharding for messages.
- Use consistent hashing.
- Multi-region deployment.
The system must support eventual consistency and handle millions of concurrent connections.
12. How do you ensure observability in large systems?
Observability enables teams to understand system behavior and diagnose issues effectively.
It consists of three pillars:
- Logs
- Metrics
- Traces
Centralized logging systems aggregate logs from all services. Metrics track performance indicators such as latency and error rates. Distributed tracing tracks request flow across services.
Tools like Prometheus, Grafana, and OpenTelemetry are commonly used. Observability is essential for maintaining reliability in complex distributed architectures.
13. How would you design an e-commerce platform at scale?
An e-commerce platform includes multiple independent services:
- Product catalog
- Inventory management
- Order processing
- Payment service
- Search service
Design decisions:
- Use caching for product pages.
- Use message queues for order processing.
- Use database replication.
- Use CDN for images.
- Implement inventory locking to avoid overselling.
Sharding by product ID or user ID ensures scalability.
14. How would you refactor a monolithic system into microservices?
Refactoring a monolith into microservices requires gradual decomposition.
Steps include:
- Identify bounded contexts and business domains.
- Extract independent modules as services.
- Introduce APIs for communication.
- Gradually migrate traffic.
- Implement service discovery and monitoring.
Strangler pattern is often used, where new services replace parts of the monolith incrementally.
This approach reduces risk while improving scalability and maintainability.
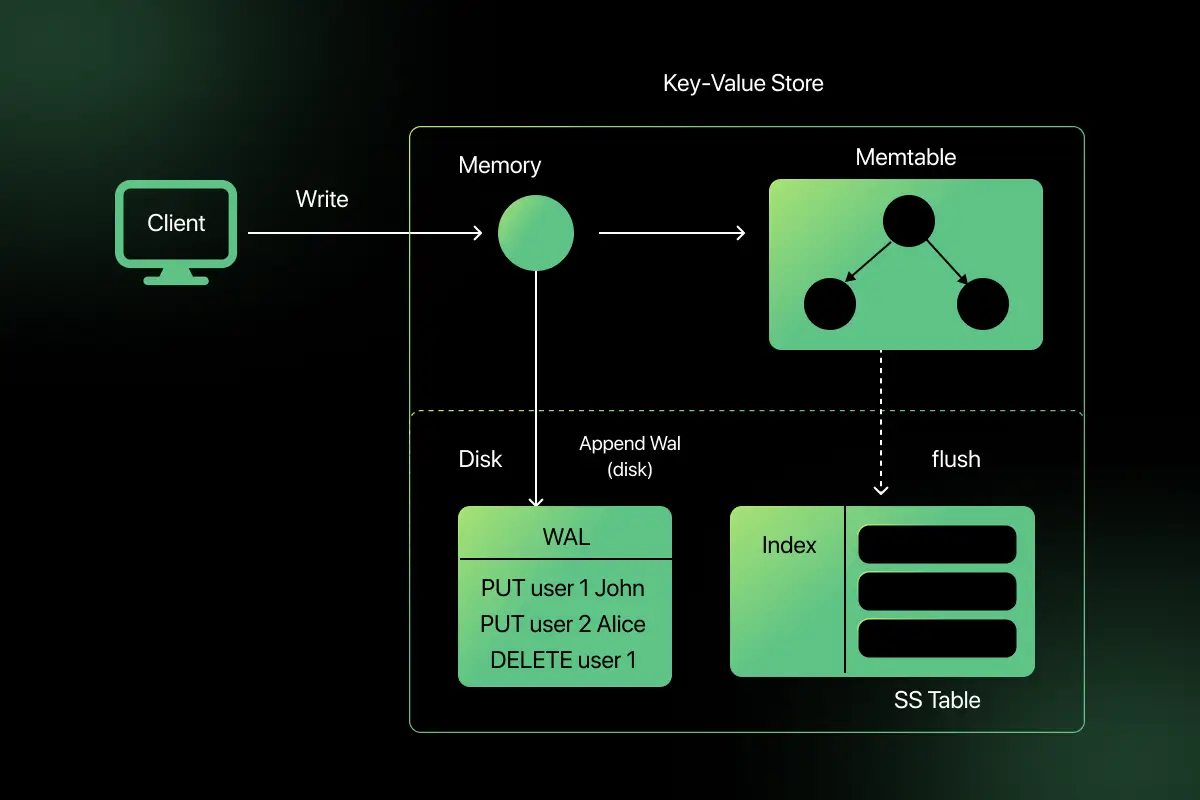
15. How would you design a distributed key-value store?
A distributed key-value store must provide scalability and availability.
Core concepts:
- Partitioning using consistent hashing
- Replication for fault tolerance
- Gossip protocol for cluster communication
- Eventual consistency model
Data is distributed across nodes using hash-based partitioning. Replication ensures durability. Systems like DynamoDB and Cassandra use this architecture.
Trade-offs must be made between consistency and availability.
16. How do you secure APIs in distributed architecture?
Securing APIs involves multiple layers of protection.
Key measures include:
- HTTPS encryption
- OAuth 2.0 or JWT authentication
- Role-based access control
- API gateways for centralized enforcement
- Rate limiting
- Input validation
- Logging and monitoring
Zero Trust principles ensure that no service is implicitly trusted. Security must be integrated into design, not added later.
17. How would you design a global load-balancing system?
A global load balancer distributes traffic across multiple geographic regions.
Architecture:
- DNS-based routing
- Health checks
- Geo-based routing
- Failover mechanisms
If one region fails, traffic automatically routes to another region. Latency-based routing improves user experience.
Global load balancing ensures availability and performance at worldwide scale.
18. What are common bottlenecks in distributed systems?
Common bottlenecks include:
- Database write contention
- Network latency
- Synchronous service dependencies
- Poor indexing
- Single points of failure
- Inefficient caching strategy
For example, if all services depend synchronously on one authentication service, its failure can cascade across the system.
Identifying bottlenecks requires monitoring latency, throughput, and resource utilization
19. How would you design a multi-region high-availability system?
A multi-region system ensures service continuity across geographic locations.
Design elements:
- Active-active deployment across regions
- Data replication
- Global load balancer
- Automated failover
- Consistency management
Challenges include:
- Replication lag
- Data conflicts
- Increased latency
Trade-offs must balance consistency, availability, and performance.
20. What trade-offs do you consider between consistency, availability, and performance?
Distributed systems must balance trade-offs defined by the CAP theorem.
- Strong consistency may increase latency.
- High availability may allow stale reads.
- Performance optimizations may reduce strict guarantees.
For example, financial systems prioritize consistency over availability, while social media platforms prioritize availability and performance.
Architectural decisions depend on business requirements, tolerance for inconsistency, and acceptable downtime.
Scenario-Based Questions for System Design Interviews
1. A news website experiences heavy traffic during breaking news events and crashes frequently. How would you redesign the system to handle sudden traffic spikes?
To handle sudden traffic spikes, the system must support horizontal scalability and traffic distribution. The first step is to place a load balancer in front of multiple stateless application servers, so incoming requests are distributed evenly. Static assets such as images and scripts should be served via a CDN to reduce load on origin servers.
Caching frequently accessed pages using Redis or an in-memory cache reduces repeated database queries. The database can be replicated for read scalability. Auto-scaling groups can automatically add more servers during peak traffic. This design ensures availability and stability during traffic surges.
2. A startup stores all application data in a single database, and performance is degrading as user growth increases. What architectural changes would you suggest?
As data volume grows, a single database becomes a bottleneck. The system can be improved by introducing read replicas to handle read-heavy traffic. Frequently accessed data should be cached using a distributed cache like Redis.
If the write volume grows significantly, database sharding can distribute data across multiple nodes. Separating services (e.g., user service and order service) into independent databases can also reduce contention. These changes improve scalability and reduce load on the primary database.
3. You are designing an online ticket booking system. How would you prevent overselling of tickets during high-demand events?
Overselling occurs when multiple users attempt to book the same seat simultaneously. To prevent this, the system must enforce strong consistency on seat allocation.
Techniques include database transactions with row-level locking or optimistic locking using version numbers. A distributed locking mechanism (e.g., Redis-based lock) can ensure only one transaction updates a seat at a time.
Additionally, a short reservation timeout system can temporarily block seats while users complete payment. This approach balances consistency and user experience while maintaining scalability.
4. A notification system sometimes delays message delivery during peak traffic. How would you redesign it to ensure reliable and scalable delivery?
Delays often indicate synchronous processing or resource saturation. The system should be redesigned to use asynchronous messaging through a message queue such as Kafka or RabbitMQ.
Incoming notification requests should be written to the queue, and worker services should process messages independently. Horizontal scaling of workers ensures high throughput. Implementing retry mechanisms and dead-letter queues ensures reliability.
This event-driven architecture improves performance and prevents delays under heavy load.
5. You are tasked with designing a globally distributed financial transaction system that must maintain consistency while supporting millions of users. How would you approach this?
A financial system requires strong consistency and fault tolerance. The architecture should use distributed databases supporting consensus protocols such as Raft. Writes should go through a leader node to maintain consistency.
Multi-region deployment should use active-passive or carefully managed active-active setups with strong replication controls. Idempotency keys must prevent duplicate transactions.
Security must include encryption, authentication, audit logging, and fraud detection services. The design must carefully balance latency and consistency, prioritizing correctness over availability when necessary.
Final Words
System design interviews evaluate not just knowledge, but structured thinking, trade-off analysis, and real-world architectural reasoning. Understanding scalability, reliability, consistency, and performance trade-offs is essential for designing modern distributed systems.
Focus on clear communication, structured problem breakdown, and explaining why you choose certain design decisions. With consistent practice and exposure to real-world scenarios, you can confidently approach system design interviews at any level.
FAQs
Common system design interview questions include designing scalable systems like URL shorteners, chat applications, social media platforms, payment systems, and distributed databases. Interviewers focus on scalability, reliability, consistency models, and architectural trade-offs.
To prepare for a system design interview, start by understanding core concepts such as scalability, load balancing, caching, CAP theorem, and database design. Practice designing simple systems step by step and clearly explaining your architectural decisions.
Scalability is critical in system design interviews because interviewers assess how your design handles increasing users, traffic, and data. A scalable system ensures performance stability through horizontal scaling, caching, partitioning, and distributed architecture.
Interviewers evaluate system design answers based on clarity of thought, requirement analysis, architecture decisions, trade-off discussion, and understanding of distributed systems concepts such as consistency, availability, and fault tolerance.
Key trade-offs in system design interviews include consistency vs availability, performance vs cost, strong consistency vs eventual consistency, vertical vs horizontal scaling, and monolithic vs microservices architecture. Demonstrating awareness of these trade-offs shows strong architectural understanding.


Aarthy is a passionate technical writer with diverse experience in web development, Web 3.0, AI, ML, and technical documentation. She has won over six national-level hackathons and blogathons. Additionally, she mentors students across communities, simplifying complex tech concepts for learners.


Aarthy is a passionate technical writer with diverse experience in web development, Web 3.0, AI, ML, and technical documentation. She has won over six national-level hackathons and blogathons. Additionally, she mentors students across communities, simplifying complex tech concepts for learners.
Related Posts

Computer Networks Interview Questions and Answers
Are you preparing for a networking interview and wondering what type of questions you might face? Computer Networks is a core …


Warning: Undefined variable $post_id in /var/www/wordpress/wp-content/themes/placementpreparation/template-parts/popup-zenlite.php on line 1050
so far feels like...
