Data Warehouse Architecture Explained
Many students understand what a data warehouse is, but often get confused about how it actually works internally. This is where data warehouse architecture becomes important, as it defines how data is organized and managed inside a data warehouse system.
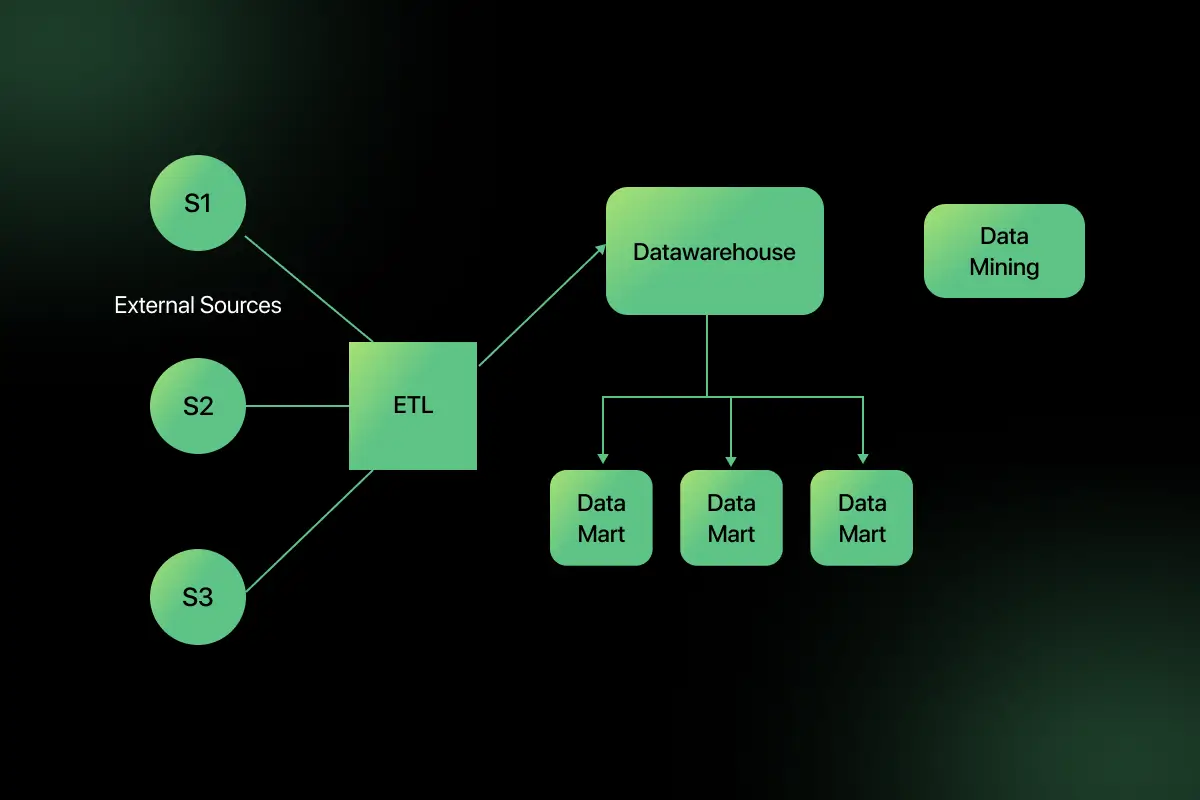
Data warehouse architecture explains how data flows from multiple sources, gets processed through ETL operations, is stored in a centralized repository, and is finally used for reporting and analytics.
In this article, we will learn what data warehouse architecture is, its components, types, working process, and how it supports modern data analytics systems.
What is Data Warehouse Architecture?
Data warehouse architecture refers to the structural design that defines how data is collected from multiple sources, transformed, and stored in a centralized repository, and accessed for reporting and analytics.
The architecture of a data warehouse organizes different components such as data sources, ETL processes, storage systems, and analytical tools so they work together efficiently.
This structure allows organizations to store large volumes of historical data and query it quickly for business intelligence and decision-making.
Why Do We Need Data Warehouse Architecture?
A well-designed data warehouse architecture helps organizations manage and analyze large volumes of data collected from different systems. It provides a structured way to store, process, and access data for business insights without impacting daily operational databases.
The main reasons for using data warehouse architecture include:
- Integrating data from multiple systems, such as transactional databases, CRM platforms, and external sources into a single repository.
- Improving query performance so analytical queries run faster without slowing down operational applications.
- Supporting analytics and reporting by providing clean and organized data for dashboards, reports, and business intelligence tools.
- Maintaining data consistency by transforming and standardizing data before storing it in the warehouse.
Components of Data Warehouse Architecture
The components of data warehouse architecture define how data moves from different sources to analytical tools. Each component plays a specific role in efficiently collecting, processing, storing, and analyzing data.
1. Data Sources
Data warehouses collect information from multiple operational systems. These sources generate the raw data that will later be processed and stored.
Common data sources include:
- Transactional databases that store daily business transactions
- CRM systems that manage customer information
- ERP systems are used for enterprise operations such as finance and inventory
- External data sources such as APIs, files, or third-party datasets
2. ETL Process (Extract, Transform, Load)
The ETL process prepares raw data before it is stored in the warehouse.
The main stages include:
- Data extraction – collecting data from multiple source systems
- Data cleaning – removing errors, duplicates, and inconsistent values
- Data transformation – converting data into a consistent format suitable for analysis
- Loading into the warehouse – storing the processed data in the central repository
3. Data Warehouse Storage
This is the central repository where processed and structured data is stored.
The storage layer is optimized for analytical queries and allows organizations to store large volumes of historical data.
4. Data Marts
Data marts are smaller, department-specific subsets of the data warehouse.
They allow teams such as marketing, finance, or sales to access relevant data quickly without querying the entire warehouse.
5. OLAP Server
An OLAP (Online Analytical Processing) server enables multidimensional data analysis.
It helps users perform complex queries, aggregations, and trend analysis efficiently.
6. Reporting and BI Tools
These tools allow users to analyze and visualize data stored in the warehouse.
Examples include:
- Dashboards that display key performance indicators
- Reporting tools used for generating business reports
- Analytics platforms are used for advanced data analysis and decision-making

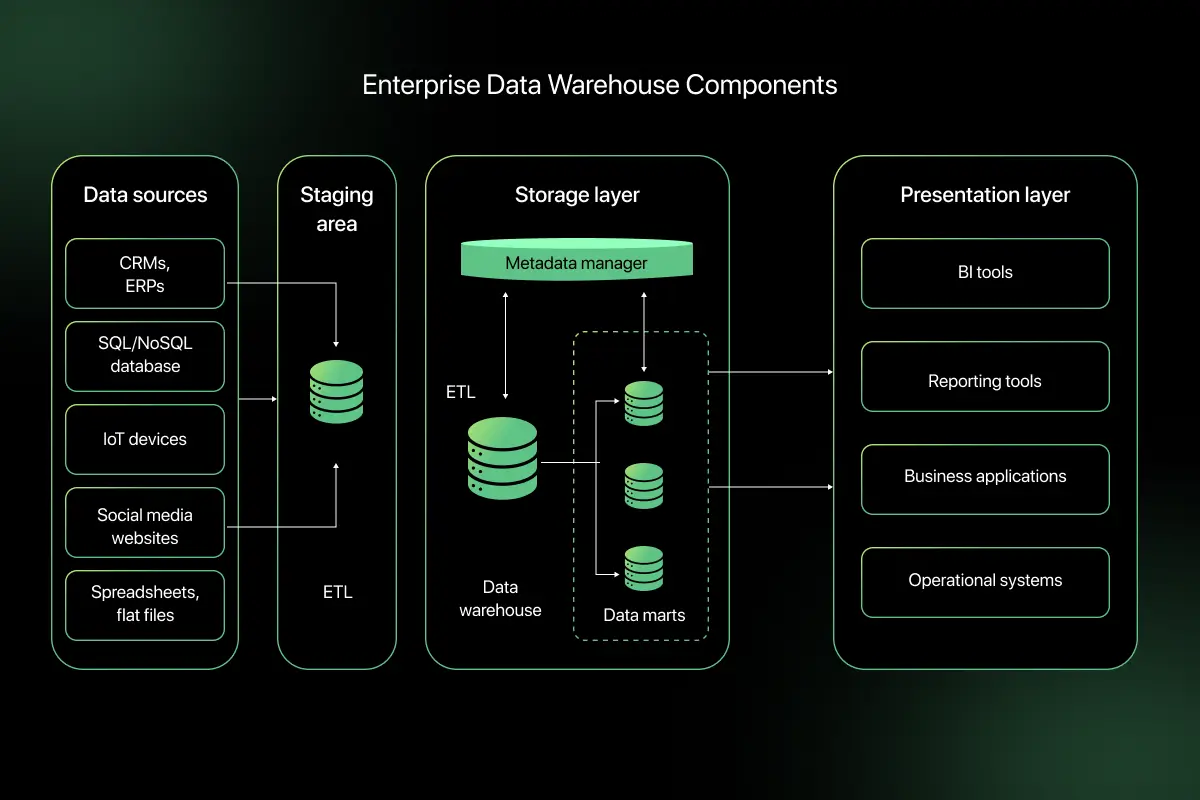
Data Warehouse Architecture Diagram and Working Flow
Learning data warehouse architecture involves understanding how data sources, ETL pipelines, and storage layers work together to support analytics and business intelligence systems.
- Step 1: Data Collection from Multiple Sources: Data is first collected from various operational systems such as transactional databases, CRM platforms, ERP systems, and external data sources. These systems generate large volumes of raw data that represent daily business activities.
- Step 2: Data Extraction and ETL Processing: The ETL (Extract, Transform, Load) process extracts data from the source systems and prepares it for storage in the warehouse. During this stage, the data is cleaned, standardized, and transformed into a consistent format to ensure accuracy and reliability.
- Step 3: Data Storage in the Central Data Warehouse: After transformation, the processed data is loaded into the central data warehouse. This repository is optimized for analytical queries and stores large volumes of structured and historical data.
- Step 4: Creation of Data Marts for Departments: Data marts are created as smaller subsets of the main warehouse to serve specific departments such as marketing, finance, or sales. These data marts allow teams to access relevant data quickly without querying the entire warehouse.
- Step 5: Data Analysis Using BI and Reporting Tools: Business intelligence tools and analytics platforms access the warehouse or data marts to analyze the data. These tools generate reports, dashboards, and visualizations that help organizations monitor performance and make informed decisions.
Types of Data Warehouse Architecture
The types of data warehouse architecture define how different layers of a data warehouse system are organized to collect, process, store, and analyze data. Depending on the complexity of the system and the analytical requirements, organizations can implement different architectural models.
The most commonly discussed architectures include single-tier, two-tier, and three-tier architectures, each designed to handle data processing and analytical workloads in different ways.
1. Single Tier Architecture
The single-tier architecture attempts to minimize the amount of data stored across different systems by reducing data redundancy. In this model, the data warehouse and analytical tools operate within a single layer, meaning there is little separation between data storage and data processing.
Although the goal of this architecture is to simplify the system and eliminate unnecessary duplication of data, it is rarely used in real-world data warehouse implementations. Most organizations require multiple layers to manage large datasets efficiently, support complex queries, and maintain system scalability.
2. Two-Tier Architecture
In two tier architecture, the client application communicates directly with the data warehouse. Users send analytical queries from their applications, and the warehouse processes these queries and returns the results.
This architecture can provide faster query performance because there are fewer layers involved in the communication process.
However, it has limited scalability, especially when many users access the system simultaneously. As organizations grow and require more advanced analytics, the two-tier model often becomes difficult to manage.
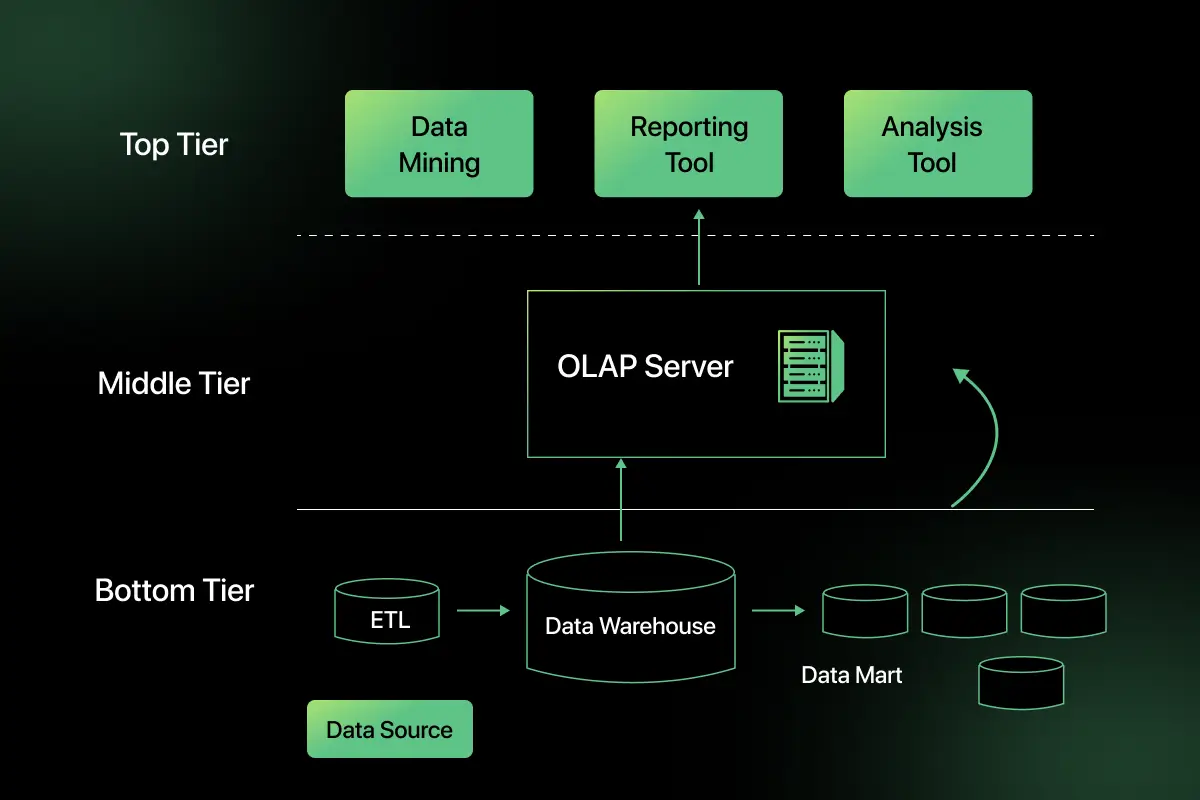
3. Three-Tier Architecture
The three-tier architecture is the most widely used model in modern data warehouse systems because it separates the system into multiple layers, improving scalability, security, and performance.
This architecture consists of three main layers:
- Bottom tier – Database Server: The bottom tier is responsible for storing the data warehouse database. It collects data from various sources through ETL processes and stores structured, historical data optimized for analytical queries.
- Middle tier – OLAP Server: The middle tier acts as an analytical processing layer using OLAP (Online Analytical Processing). It processes complex queries, performs aggregations, and allows users to analyze large datasets efficiently.
- Top tier – Reporting and Analytics Tools: The top tier contains the user-facing tools such as dashboards, reporting platforms, and business intelligence applications. These tools allow analysts, managers, and decision makers to visualize and interpret the data stored in the warehouse.
Because of its layered design, three tier architecture is considered the standard approach for building scalable and efficient data warehouse systems.
Single Tier vs Two Tier vs Three Tier Data Warehouse Architecture
Different data warehouse architectures are designed to handle data processing and analytics in different ways.
The following table compares various data warehouse architecture models based on scalability, system complexity, and their common usage in real-world applications.
| Architecture Type | Layers | Scalability | Complexity | Common Usage |
| Single Tier Architecture | Single layer where storage and analytics are integrated | Very low scalability | Low complexity | Mostly theoretical; rarely used in real-world systems |
| Two-Tier Architecture | Client layer and data warehouse server | Moderate scalability | Moderate complexity | Small to medium analytical systems where direct client access is acceptable |
| Three Tier Architecture | Bottom tier (database server), middle tier (OLAP server), top tier (BI tools) | High scalability | Higher complexity | Most common architecture used in enterprise data warehouses and business intelligence systems |
Advantages and Limitations of Data Warehouse Architecture
A well-designed data warehouse architecture helps organizations manage large volumes of data efficiently and support advanced analytics.
However, like any complex data system, it also comes with certain limitations that organizations must consider.
Advantages
- Better Decision Making: Data warehouse architecture provides a centralized repository of structured and historical data. This allows organizations to analyze trends, generate insights, and make more informed business decisions.
- Improved Data Consistency: Data from multiple sources is cleaned, transformed, and standardized before being stored in the warehouse. This ensures consistent and reliable data for reporting and analysis.
- Faster Analytics and Query Performance: Since the data warehouse is optimized for analytical queries, users can run complex queries and generate reports much faster compared to operational databases.
- Historical Data Storage: Data warehouses store large amounts of historical data over long periods. This helps organizations analyze past performance, identify patterns, and predict future trends.
Limitations
- High Implementation Cost: Building and maintaining a data warehouse architecture requires significant investment in infrastructure, tools, and skilled professionals.
- Complex Data Integration: Integrating data from multiple systems, such as databases, applications, and external sources, can be technically complex and time-consuming.
- Maintenance Overhead: Data warehouses require continuous monitoring, updates, and ETL maintenance to ensure that the data remains accurate, secure, and up to date.
Real World Use Cases of Data Warehouse Architecture
Organizations across different industries use data warehouse architecture to store and analyze large volumes of structured data.
Large companies like Amazon and Netflix rely on data warehouse architecture to analyze customer behavior, monitor business performance, and identify market trends.
By integrating information from multiple systems, businesses can generate insights that support better decision-making and long-term planning.
Banking Analytics: Banks use data warehouses to analyze customer transactions, credit history, and financial trends. This helps financial institutions detect fraud, evaluate credit risk, and understand customer spending behavior.
E-commerce Sales Analysis: Online retailers collect data from website activity, purchase records, and customer interactions. Using data warehouse architecture, companies can analyze sales patterns, monitor product performance, and personalize marketing strategies.
Healthcare Data Analysis: Healthcare organizations manage large amounts of patient data, medical records, and treatment outcomes. Data warehouses help hospitals and research institutions analyze this information to improve patient care and support medical research.
Telecom Customer Insights: Telecom companies analyze call records, network usage, and customer service interactions using data warehouses. This allows them to identify usage trends, improve network performance, and design better service plans for customers.
Common Confusion: Data Warehouse vs Database vs Data Lake
Many beginners confuse databases, data warehouses, and data lakes because all three systems are used to store and manage data. However, they serve different purposes and are designed for different types of data processing and analysis.
Database: A database is designed to store and manage current operational data used by applications for daily transactions. It is optimized for fast insert, update, and delete operations. Examples include banking transaction systems, order management systems, and user account databases.
Data Warehouse: A data warehouse is built specifically for analytics and reporting rather than daily operations. It collects data from multiple databases and other sources, transforms it through ETL processes, and stores large volumes of historical data that can be analyzed to generate business insights.
Data Lake: A data lake stores large amounts of raw and unstructured data, such as logs, images, videos, and sensor data. Unlike data warehouses, data lakes do not require data to be structured before storage, making them useful for big data processing and advanced analytics like machine learning.
In simple terms, databases handle operational data, data warehouses support analytical reporting, and data lakes store raw data for large-scale processing and advanced analytics.
Important Concepts and Interview Questions
- Explain the architecture of a data warehouse.
- What are the main components of data warehouse architecture?
- What is ETL in data warehouse systems?
- Why is three-tier architecture commonly used in data warehousing?
If you want to test your understanding of data warehouse architecture concepts, try solving SQL MCQs covering data storage models, query processing, and database fundamentals used in analytics systems.
Also, SQL interview questions for practice help reinforce concepts commonly asked in database, data engineering, and analytics-related interview discussions.
Final Words
Data warehouse architecture plays a crucial role in organizing and managing large volumes of data for analytics and decision-making.
Understanding its components, types, and working flow helps build efficient business intelligence systems.
Explore More Architecture Blogs
- Database Management System
- Microservices
- Web Application
- REST API and API Gateway
- Distributed Systems
- OSI Security Model
- Cloud Computing
- Docker
- Kubernetes
- SAP
- SQL Server
- Spring Boot
- Java
- Linux
- Angular
- Selenium
FAQs
Data warehouse architecture refers to the structural design that defines how data is collected from multiple sources, processed through ETL operations, stored in a centralized repository, and accessed for reporting and analytics.
The main components include data sources, ETL processes, data warehouse storage, data marts, OLAP servers, and reporting or BI tools. These components work together to collect, process, store, and analyze large volumes of business data.
The common types include single-tier, two-tier, and three-tier architecture. Among these, three tier architecture is the most widely used because it separates storage, processing, and presentation layers.
ETL is important because it extracts data from multiple sources, cleans and transforms it into a consistent format, and loads it into the data warehouse. This ensures accurate, reliable, and analysis-ready data.
A database stores current operational data used for daily transactions, while a data warehouse stores historical data collected from multiple systems for reporting, analytics, and business intelligence.
Common tools include ETL tools such as Informatica and Talend, data warehouse platforms like Amazon Redshift and Snowflake, and BI tools such as Tableau, Power BI, and Looker for reporting and analytics.


Aarthy is a passionate technical writer with diverse experience in web development, Web 3.0, AI, ML, and technical documentation. She has won over six national-level hackathons and blogathons. Additionally, she mentors students across communities, simplifying complex tech concepts for learners.


Aarthy is a passionate technical writer with diverse experience in web development, Web 3.0, AI, ML, and technical documentation. She has won over six national-level hackathons and blogathons. Additionally, she mentors students across communities, simplifying complex tech concepts for learners.
Related Posts

Difference between Main memory and Secondary memory
Have you ever noticed that unsaved work disappears after a power failure, while your documents, photos, and applications remain available …
Warning: Undefined variable $post_id in /var/www/wordpress/wp-content/themes/placementpreparation/template-parts/popup-zenlite.php on line 1050
so far feels like...
